
分解(decompose)
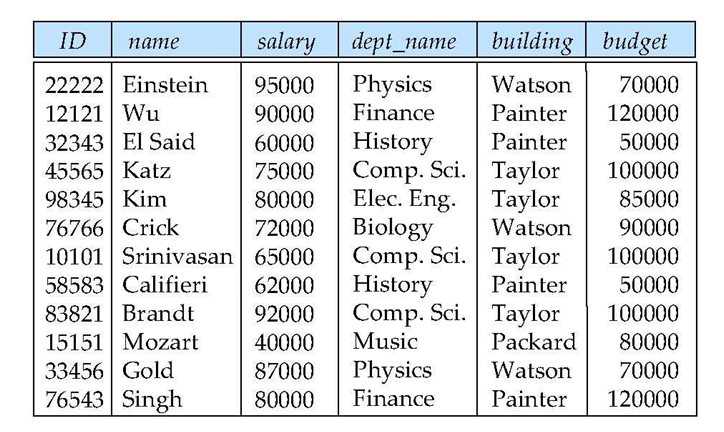
- 如果分解后无法重建原始信息,那么就是有损分解(Lossy Decomposition),反之则为无损分解(Lossless-Join Decomposition)

- 所以我们需要一个理论来告诉我们怎么合理的分解关系。好的分解要做到:
- 无损分解
- 依赖保存
- BCNF 分解可以保证无损,3NF 可以保证依赖保存,但是 3NF 无法保证没有冗余,因此需要在 BCNF 和 3NF 间权衡
第一范式(First Normal Form)
- 如果一个域的元素被认为是不可分割的单元,则该域是原子的。
- 非原子域的示例:
- 名称集合,复合属性
- 可以分解为部分的标识号,例如 CS101
- 如果关系模式 R 的所有属性的域都是原子的,则关系模式 R 符合第一范式。
- 非原子值会使存储变得复杂,并鼓励数据的冗余(重复存储)。
- 例如:每个客户都存储了一组账户,每个账户都存储了一组所有者。
- 我们假设所有关系都符合第一范式(并在第 22 章: 基于对象的数据库中重新讨论这一点)。
原子性
- 原子性实际上是与域的元素如何使用相关的属性。
- 例如,字符串通常被认为是不可分割的。
- 假设学生被赋予类似 SE0012 或 EE1127 的字符串形式的学号。
- 如果提取前两个字符来确定学院,那么学号的域就不是原子的。
- 这样做是一个坏主意:会导致信息被编码在应用程序而不是数据库中。
:::
第二范式(Second Normal Form)
- 数据库表中不存在非关键字段对任一候选键的部分函数依赖,也即所有非关键字段都完全依赖于任意一组候选关键字。
- 2NF 的违例只会出现在候选键由超过一个字段构成的表中,因为对单关键字字段不存在部分依赖问题。
例子
给定关系模式的函数依赖集合如下:
在这个例子中,候选键只有一个,即
我们可以观察到,属性
为了使关系模式满足第二范式,我们需要进行分解,将属性
关系模式 1:
关系模式 2:
关系模式 3:
这样,每个关系模式都满足第二范式,并且保留了原始关系模式的函数依赖。
函数依赖(Functional Dependencies)
- 函数依赖是对合法关系集合的约束条件。
- 要求某个属性集合的值唯一确定另一个属性集合的值。
- 函数依赖是对键的概念的一种推广。
- 定义为:
超码(super key)- 属性
- 在函数依赖
平凡(trivial)的。因为对于任意的关系- 例如:
- 例如:
- 在函数依赖
- 在函数依赖
函数依赖与超键
当且仅当
当且仅当满足以下条件时,
- 对于任何
函数依赖允许我们表达无法使用超键来表示的约束。考虑以下模式:
- 我们期望以下函数依赖成立:
- 但我们不期望以下函数依赖成立:
- 我们期望以下函数依赖成立:
函数依赖的作用
我们使用函数依赖来进行以下操作:
- 检验关系是否在给定的函数依赖集合下合法。
- 如果关系
满足(satisfy)
- 如果关系
- 指定对合法关系集的约束。
- 如果在关系模式
成立(holds on)。
- 如果在关系模式
注意:一个关系模式的特定实例可能满足一个函数依赖,即使该函数依赖不在所有合法实例上成立。
例如,
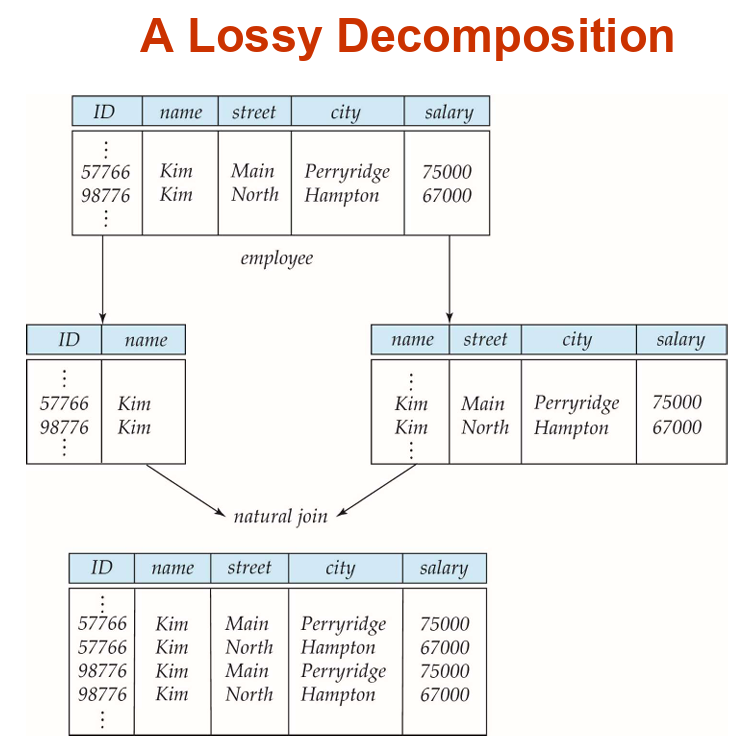
无损连接与分解(Lossless-join Decomposition)
- 对于关系
- 如果一个从
- 上述是保证无损分解的充分条件。
函数依赖闭包
- 如果两个函数依赖集的闭包相等,那么我们就说这两个函数依赖集是等价的
- 我们可以通过反复应用 Armstrong 公理(Armstrong's Axioms)来找到
- 自反性:如果
- 扩充性:如果
- 传递性:如果
- 自反性:如果
- 这些规则是完备(sound)的(生成所有成立的函数依赖)且合理(complete)的(仅生成实际成立的函数依赖)。
- 附加规则:
- 并集规则:如果
- 分解规则:如果
- 伪传递性规则:如果
- 并集规则:如果
- 这些附加规则可以从 Armstrong 的公理推导出来,并且可以用于计算函数依赖的闭包。

属性集闭包(Closure of Attribute Sets)
- 定义为:
- 也就是通过函数依赖确定

属性集闭包与函数依赖
- 我们有关系:
- 因此可以通过计算属性集闭包来计算函数依赖
属性集闭包与超键
- 我们有关系:
- 因此通过属性集可以确定
属性集闭包与函数依赖闭包
通过属性集闭包计算函数依赖闭包:
- 对每个
- 对每个
- 输出
规范化的目标
- 给定一个关系模式 R 和函数依赖集合 F,判断关系模式 R 是否处于“良好”的形式。
- 如果关系模式 R 不处于“良好”的形式,则将其分解为一组关系模式
- 分解应该是无损连接(lossless-join)的分解,即通过连接分解后的关系能够恢复到原始关系模式。
- 最好的情况是分解应该是依赖保持的,即在分解后的每个关系模式上仍然能够保持原始的函数依赖关系。
规范覆盖(Canonical Cover)
- 规范覆盖(Canonical Cover)是指函数依赖集合中的一组“最小”等价函数依赖,它不包含冗余的依赖关系或冗余的依赖关系部分。函数依赖集
- 函数依赖集合中的依赖关系可能存在冗余的依赖关系,可以从其他依赖关系中推导出来。例如,在集合
- 函数依赖的部分可能也是冗余的。例如,在右侧的依赖集合
- 直观地说,规范覆盖是等价于函数依赖集合
计算规范覆盖
- 计算函数依赖集合
- 重复以下步骤:
- 使用并集规则(union rule)替换
- 查找具有冗余属性的函数依赖
- 如果找到冗余属性,则从
- 使用并集规则(union rule)替换
- 直到
- 重复以下步骤:
- 需要注意的是,删除一些冗余属性后,可能会使并集规则再次适用,因此需要重新应用并集规则。
- 通过执行上述步骤,最终得到的函数依赖集合

冗余属性(Extraneous Attributes)
冗余属性(Extraneous Attributes)是指在给定的函数依赖集合中,某个属性在依赖关系中是冗余的,可以被删除而不影响函数依赖的表达。
例如,给定函数依赖集合
对于函数依赖集合
需要注意的是,上述情况中,逆向的蕴含关系在每种情况下都是显而易见的,因为“更强”的函数依赖总是蕴含着“更弱”的函数依赖。
验证冗余属性
- 要检查一个属性
- 在
- 验证
- 在
- 方法二,利用
- 在
- 验证
BCNF 范式(Boyce-Codd Normal Form)
关系模式 R 在 BCNF(Boyce-Codd 范式)中,如果对于
换言之。BCNF 意味着在关系模式中每一个决定因素都包含候选键,也就是说,只要属性或属性组 A 能够决定任何一个属性 B,则 A 的子集中必须有候选键。BCNF 范式排除了任何属性(不光是非主属性,2NF 和 3NF 所限制的都是非主属性)对候选键的传递依赖与部分依赖。
示例中的关系模式不符合 BCNF:
因为
又例如:
假设仓库管理关系表为
所以,
仓库 ID 是决定因素,但仓库 ID 不包含候选键。
同样的,管理员 ID 也是决定因素,但不包含候选键。
所以该表不满足 BCNF。
检查 BCNF
- 如何检查非平凡依赖关系
- 计算函数依赖的闭包
- 验证是否满足
- 计算函数依赖的闭包
- 如何检查关系模式
- 对于每个非平凡函数依赖
- 对于每个非平凡函数依赖
- 优点:
- 不需要计算所有可能的函数依赖
- 不需要计算所有可能的函数依赖
分解模式为 BCNF
- 如果我们有模式

BCNF 与依赖保留(BCNF and Dependency Preservation)

- 设
- 如果一个分解是依赖保持的(dependency preserving),则满足以下条件:
- 如果不满足上述条件,那么检查违反函数依赖的更新可能需要计算连接操作,这是非常昂贵的。换句话说,如果分解不是依赖保持的,那么在更新操作中检查函数依赖的违规可能需要进行昂贵的连接计算。

验证依赖保留

缺点
- 在某些情况下,BCNF 不具备依赖保持性,并且在更新操作中高效地检查函数依赖的违规非常重要。
- 解决方案是定义一个较弱的规范形式,称为第三范式(3NF)。
- 第三范式允许一定程度的冗余(带来相关问题;我们将在稍后看到示例),但可以在单个关系上检查函数依赖,而无需计算连接操作。
- 总是存在一种无损连接、依赖保持的分解,使其满足第三范式。
第三范式(Third Normal Form)
在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式
一个关系模式 R 在第三范式(3NF)中,如果对于 F 中的所有
如果一个关系符合 BCNF,那么它也符合 3NF(因为在 BCNF 中,上述的前两个条件之一必须成立)。
第三个条件是 BCNF 的最小放宽,以确保依赖性的保持(稍后会看到为什么)。
例子:
表:
该表中候选字段只有“学号”,于是“学号”做主键。由于主键是单一属性,所以不存在非主属性对主键的部分函数依赖的问题,所以必然满足第二范式。但是存在如下传递依赖:
学院地点和学院电话传递依赖于学号,而学院地点和学院电话都是非关键字段,即表中出现了“某一非关键字段可以确定出其他非关键字段”的情况,于是违反了第三范式。
检查第三范式
给定关系模式
对于每个非平凡的函数依赖- 检查
- 如果
- 这个测试相对来说更加昂贵,因为它涉及到候选键的查找。
- 检查
有趣的是,测试是否符合第三范式已被证明是 NP 困难问题的。然而,将关系分解为第三范式(稍后会进行描述)可以在多项式时间内完成。
分解为第三范式
步骤:
- 计算规范覆盖
- 生成新关系
- 找到
- 如果没有模式
- 输出
- 为什么 3NF 是依赖保存的:因为每一个依赖




3NF VS BCNF
总是可以将一个关系分解为一组符合第三范式(3NF)的关系,满足以下条件:
- 分解是无损的,即通过连接分解后的关系能够恢复到原始关系。
- 依赖关系得到保留,即分解后的每个关系仍然能够保持原始的函数依赖关系。
总是可以将一个关系分解为一组符合 BCNF(Boyce-Codd 范式)的关系,满足以下条件:
- 分解是无损的,即通过连接分解后的关系能够恢复到原始关系。
- 可能无法保留所有的依赖关系,即在分解后的关系中,可能无法保持原始的所有函数依赖关系。
换句话说,对于 3NF,我们可以找到一组关系进行分解,使得分解后的关系满足 3NF 并且保留依赖关系。而对于 BCNF,我们可以找到一组关系进行分解,使得分解后的关系满足 BCNF,但不一定能保留所有的依赖关系。
| 无损分解? | 依赖保留? | 移除冗余? | |
|---|---|---|---|
| BCNF | Y | N | Y |
| 3NF | Y | Y | N |
第三范式的冗余
在第三范式中,确实存在一些冗余问题。
以下是一个示例,展示了第三范式中冗余可能导致的问题:
假设关系模式为
| J | K | L |
|---|---|---|
| j1 | k1 | l1 |
| j2 | k1 | l1 |
| j3 | k1 | l2 |
| null | k2 | null |
在上述示例中,存在信息的重复(例如,l1 与 j1、k1 之间的关系重复出现)。同时,为了表示没有对应值的关系,使用了空值(例如,表示 j3、k2 与 l2 之间没有对应值的关系)。
此外,如果没有单独的关系将教师与部门进行映射,可能需要使用空值来表示(例如,(i_ID, dept_name)中的记录,当没有对应的关系时)。
以上是第三范式中可能出现的冗余问题的示例。
数据库设计
- 关系数据库设计的目标是:
- 满足 BCNF(Boyce-Codd 范式)。
- 保证无损连接。
- 保持依赖关系。
- 如果无法同时满足这些目标,我们需要接受以下之一:
- 缺乏依赖关系的保持。
- 由于使用了 3NF(第三范式)而导致的冗余。
- 有趣的是,SQL 并没有直接提供指定函数依赖关系的方法,除了超键(superkey)之外。虽然可以使用断言来指定函数依赖关系,但是这种方法在测试上是昂贵的,并且目前没有任何广泛使用的数据库支持它们。
- 即使我们有一个保持依赖关系的分解,使用 SQL 也无法有效地测试左侧不是关键字的函数依赖关系。
非规范化以提高性能
可能希望为了提高性能而使用非规范化的模式,例如,显示课程 ID 和标题以及先决条件需要将课程表与先决条件表进行连接。
- 备选方案 1:使用包含课程属性和先决条件属性的非规范化关系,具有上述所有属性。
- 查找速度更快。
- 更新时需要额外的空间和执行时间。
- 程序员需要额外编码工作,并可能在额外的代码中出现错误。
- 备选方案 2:使用定义为"course prereq"的物化视图。
- 利弊与上述相同,但程序员无需额外编码工作,并避免可能出现的错误。
第四范式(Fourth Normal Form)



一个关系模式
如果一个关系模式符合第四范式(4NF),那么它也符合 BCNF(Boyce-Codd 范式)。
范式之间的关系
第一范式(1NF)
非码的非平凡 | ↓ 消除非主属性对码的部分函数依赖
第二范式(2NF)
↓ 消除非主属性对码的传递函数依赖
第三范式(3NF)
↓ 消除主属性对码的部分和传递函数依赖
BC 范式(BCNF)
↓ 消除非平凡且非函数依赖的多值依赖
第四范式(4NF)
↓ 消除不是由候选码所蕴含的连接依赖
第五范式(5NF)