故障分类
- 事务故障:
- 逻辑错误:由于某些内部错误条件(例如 A 的余额不足,无法扣款),事务无法完成。
- 系统错误:数据库系统必须由于错误条件(例如死锁)终止活动事务。
- 系统崩溃:
- 由于电源故障或其他硬件或软件故障,系统崩溃。
- 停止故障假设:
- 假设非易失性存储内容在系统崩溃时不会被破坏。
- 数据库系统具有许多完整性检查来防止磁盘数据的损坏。
- 磁盘故障:
- 磁头碰撞或类似的磁盘故障破坏了全部或部分磁盘存储。
- 假设破坏是可检测的:磁盘驱动器使用校验和来检测故障。
恢复算法
- 考虑一个将 50 美元从账户 A 转账到账户 B 的事务
- 读取(A)
- A := A - 50
- 写入(A)
- 读取(B)
- B := B + 50
- 写入(B)
- 事务
- 在这些修改中的某个修改完成之后,但两者都未完成之前,可能发生故障。
- 在没有确保事务将提交的情况下修改数据库可能会导致数据库处于不一致的状态。
- 如果在事务提交后发生故障,不修改数据库可能会导致更新丢失。
- 恢复算法分为两个部分:
- 在正常事务处理期间采取的操作,以确保存在足够的信息以从故障中恢复。
- 在发生故障后采取的操作,将数据库内容恢复到确保原子性、一致性和持久性的状态。
存储结构
- 易失性存储:
- 不会在系统崩溃后保存数据。
- 示例:主存储器、缓存存储器。
- 非易失性存储:
- 在系统崩溃后能够保存数据。
- 示例:磁盘、磁带、闪存存储器、非易失性(电池备份)RAM。
- 但仍可能发生故障导致数据丢失。
- 稳定存储:
- 一种虚构的存储形式,能够在所有故障情况下都保留数据。
- 通过在不同的非易失性介质上维护多个副本来近似实现稳定存储。
- 有关如何实现稳定存储的更多详细信息,请参阅相关书籍。
实现稳定存储(Stable-Storage Implementation)
在单独的磁盘上维护每个块的多个副本:
- 副本可以位于远程站点,以防止火灾或洪水等灾害。
- 在数据传输过程中发生故障仍可能导致不一致的副本:
- 块传输可能导致:
- 成功完成
- 部分失败:目标块包含错误的信息
- 完全失败:目标块从未更新
- 块传输可能导致:
保护存储介质免受数据传输期间的故障(一种解决方案):
执行输出操作的步骤(假设每个块有两个副本):
- 将信息写入第一个物理块。
- 当第一次写入成功完成后,将相同的信息写入第二个物理块。
- 只有在第二次写入成功完成后,输出才算完成。
由于输出操作期间的故障,块的副本可能不同。为了从故障中恢复:
- 首先找到不一致的块:
- 昂贵的解决方案:比较每个磁盘块的两个副本。
- 更好的解决方案:
- 在非易失性存储(非易失性 RAM 或磁盘的特殊区域)中记录正在进行的磁盘写操作。
- 在恢复过程中使用此信息找到可能不一致的块,并仅比较这些块的副本。
- 在硬件 RAID 系统中使用。
- 如果检测到不一致块的任一副本存在错误(校验和错误),则使用另一个副本覆盖它。如果两个副本都没有错误,但是不同,那么使用第一个副本覆盖第二个块。
- 首先找到不一致的块:
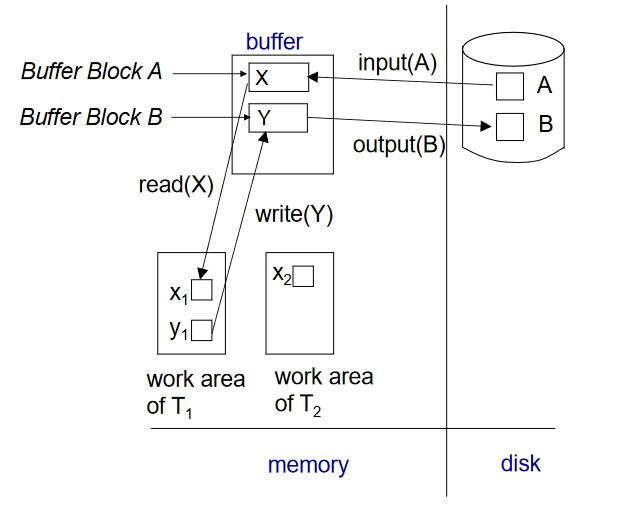
数据访问(Data Access)
- 物理块(Physical blocks)是指存储在磁盘上的块。
- 缓冲块(Buffer blocks)是临时存储在主存储器中的块。
- 磁盘和主存储器之间的块移动是通过以下两个操作发起的:
- input(B):将物理块 B 传输到主存储器。
- output(B):将缓冲块 B 传输到磁盘,并替换相应的物理块。
- 为简单起见,我们假设每个数据项适合并存储在单个块内。
恢复与原子性
为了确保在发生故障时实现原子性,我们首先将描述修改的信息输出到稳定存储中,而不修改数据库本身。
- 我们详细研究基于日志的恢复机制。
- 首先介绍关键概念。
- 然后介绍实际的恢复算法。
- 较少使用的备选方案是影子分页(在书中有简要介绍)。
基于日志的恢复
- 在稳定存储中保留一个日志。
- 日志是一系列日志记录,用于记录数据库上的更新活动。
- 当事务
- 在
- 当
- 使用日志的两种方法:
- 延迟数据库修改(Deferred database modification):需要更大的内存开销。
- 立即数据库修改(Immediate database modification):重点掌握。
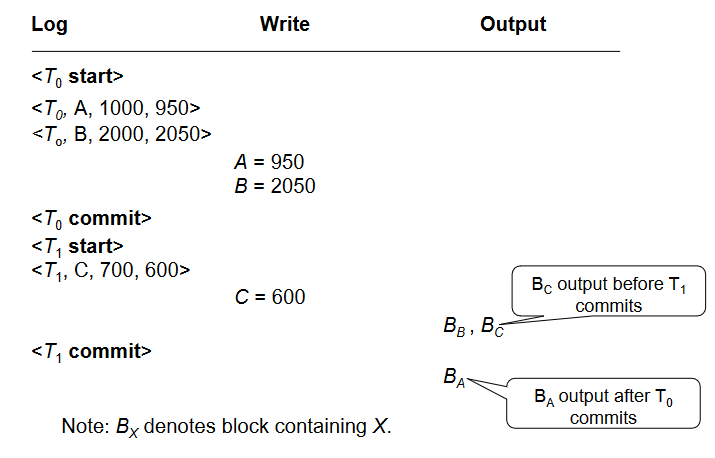
事务提交
- 日志部分:当事务的提交日志记录
- 该事务的所有先前的日志记录必须已经输出。
- 数据更新部分:当事务提交时,事务执行的写操作可能仍然在缓冲区中,并且可能稍后才被输出。
方法 1: 延迟数据库修改(Deferred Database Modification)
- 延迟数据库修改方案将所有修改记录到日志中,但将所有写操作推迟到部分提交之后执行。
- 假设事务按顺序执行:
- 开始时:事务通过向日志写入
- 过程中:执行
- 结束时:当事务部分提交(即执行完所有语句),
- 开始时:事务通过向日志写入
- 在以下情况下可能发生故障:
- 事务正在执行原始的更新操作时
- 正在进行恢复操作时
- 故障发生后的处理方法:
- 只有在日志中同时存在

- 只有在日志中同时存在
- (a) 无需执行重做操作
- (b) 由于存在
- (c) 由于
方法 2: 立即数据库修改(Immediate Database Modification)
在故障发生前的常规做法:
- 先写日志,后执行写操作:
- 必须在写入数据库项之前写入更新的日志记录。
- 我们假设日志记录直接输出到稳定存储器中。
- (稍后将了解如何在一定程度上延迟日志记录的输出)
- 写操作立即执行:
- 立即修改方案允许未提交的事务的更新操作被写入缓冲区或磁盘本身,在事务提交之前就可以进行修改。
- 输出可能发生在任意时刻:
- 更新后的块输出到稳定存储器可以在事务提交之前或之后的任何时刻发生。
- 输出的顺序是任意的:
- 输出块的顺序可以与写入顺序不同。
- 输出块的顺序可以与写入顺序不同。
- 恢复过程需要两个操作而不是一个:
- 这两个操作必须是
幂等(idempotent)的,即使操作执行多次,效果与执行一次相同。 - 在故障后进行恢复时:
- 如果日志中包含记录
- 如果日志中同时包含记录
- 如果日志中包含记录
- (a)
- (b)
- (c)
对比
- 延迟修改方案仅在事务提交时或之后才对缓冲区/磁盘执行更新,简化了恢复的某些方面,但有存储本地副本的开销
- 接下来介绍的算法都采用立即数据库修改(Immediate Database Modification)
并发控制和恢复
- 在并发事务中,所有事务共享一个单一的磁盘缓冲区和一个单一的日志。
- 一个缓冲块可以包含被一个或多个事务更新的数据项。
- 我们假设如果事务
- 也就是说,未提交事务的更新对其他事务不可见。
- 否则,如果
- 否则,如果
- 可以通过对更新的项获取独占锁,并在事务结束前保持这些锁(严格的两阶段锁定)来确保这一点。
- 不同事务的日志记录可能会交错在日志中。
撤销和重做操作
对于日志记录
对于事务的撤销操作:
- 从事务
- 对于每个日志记录
- 当事务的撤销操作完成时,写入日志记录
- 从事务
注意:这里的
重做操作:
- 对于日志记录
- 对于事务的重做操作:
- 从事务 Ti 的第一个日志记录开始向前执行。
- 对于每个日志记录
- 在此情况下不进行日志记录。
- 对于日志记录
在故障后进行恢复时:
- 如果日志包含记录
- 如果日志包含记录
- 如果日志包含记录
注意:如果事务
- 此类重做会重新执行所有原始操作,包括恢复旧值的步骤。
- 这被称为
重复历史(repeating history)。 - 首先看起来可能浪费,但大大简化了恢复过程。
(a)
(b)
(c)
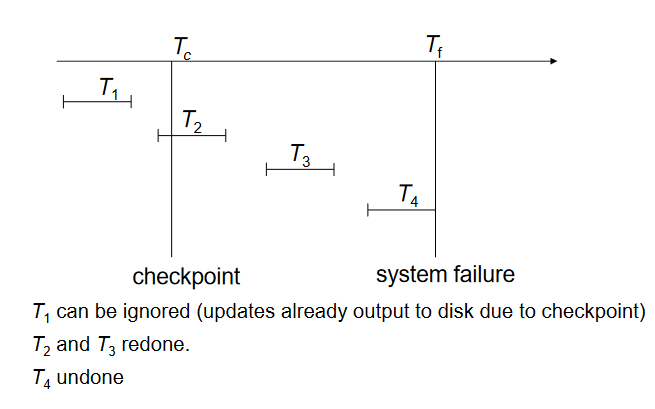
检查点(Checkpoints)
在日志中重做/撤销所有记录的事务可能非常缓慢:
- 如果系统运行时间很长,处理整个日志会耗费时间。
- 我们可能会不必要地重做已经将更新输出到数据库的事务。
通过定期执行检查点来简化恢复过程:
- 在执行检查点期间停止所有更新操作。
- 将当前驻留在主内存中的所有日志记录输出到稳定存储介质。
- 将所有修改的缓冲块输出到磁盘。
- 在稳定存储中写入日志记录
在恢复过程中:
- 从日志的末尾开始向后扫描,找到最近的
- 需要处理的事务:
L中的事务+检查点之后启动的事务,只需要重做或撤销最近在检查点之前启动的事务和检查点之后启动的事务。
- 注:在检查点之前提交或中止的事务已经将所有更新输出到稳定存储介质。
- 一些日志中早期的部分可能需要用于撤销操作。 - 继续向后扫描,直到找到
- 从日志的末尾开始向后扫描,找到最近的
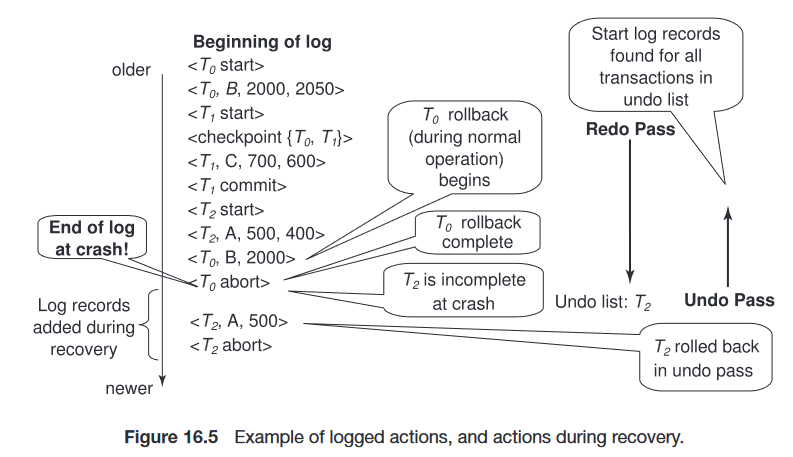
基于日志的恢复算法
日志记录(在正常操作期间):
- 事务开始时记录
- 每次更新操作都记录
- 事务结束时记录
- 事务开始时记录
事务回滚(在正常操作期间):
- 假设要回滚的事务为
- 从日志的末尾开始向后扫描,并对于
- 通过将
- 写入日志记录
- 通过将
- 一旦找到记录
- 假设要回滚的事务为
故障恢复:分为两个阶段:
第一阶段,重做阶段:重放所有事务的更新操作,无论它们是已提交、已中止还是未完成的。
- 找到最后一个
- 从上述
- 每当找到记录
- 每当找到记录
- 每当找到记录
- 每当找到记录
- 找到最后一个
第二阶段,撤销阶段:撤销所有未完成的事务。
- 从日志的末尾开始向后扫描:
- 每当找到记录
- 通过将
- 写入日志记录
- 通过将
- 每当找到记录
- 写入日志记录
- 从 undo-list 中移除
- 写入日志记录
- 每当找到记录
- 当 undo-list 为空时停止(即已为 undo-list 中的每个事务找到
- 从日志的末尾开始向后扫描:
在撤销阶段完成后,可以开始正常的事务处理。