
Chapter3 语法分析
- 正则表达式的能力有限,无法分析具体的语法细节(例如嵌套、
大纲
- 语法分析的形式化——上下文无关文法
- 语法分析算法
上下文无关文法(CFG)
- 是用来描述一个编程语言的语法结构的文法
- 和正则表达式一样,可以表示递归的规则,而且更强大
- 是正则表达式的严格超集
Chomsky 语言层级
| Chomsky hierarchy | Production(产生式) | Explanation |
|---|---|---|
| unrestricted(type 0)(自然语言) | 无严格约束 | |
| context sensitive(type 1)(上下文有关文法) | 在不同的上下文中, | |
| context free(type 2)(上下文无关文法) | 在任何 | |
| regular(type 3)(正则表达式) | 等价于正则表达式 |
- 如果一个符号由它自身定义(
- 如果一个符号有其定义的可再分的结构就是一个非终止符号(
- 要注意,
- CFG 文法规定的第一个文法的左部是开始符号,规定了该语言都满足的一个规则
- 一个处于较低层级的文法是上级文法的特例,例如 RE 就是一种特殊的 CFG
形式化定义
EBNF(Extended Backus-Naur form)
- 简化表示:
- 除非特殊说明,否则第一个产生式的左部就是初始符号
- 用小写字母表示终止符号
- 用大写字符或者
- 如果左部都为
- 特别注意:
左递归:
右递归:
结合性
中括号表示其中的符号出现 0 次或 1 次,大括号表示 0 次至无数次
推导(Derivation)与规约(Reduction)
- 如果能用一步步推导从初始符号得到需要验证的式子,那么式子就是符合规则的
- 推导就是不断用产生式的右部来替换一个非终止符
- 由终止符号构成的串称为句子(sentence),由非终止符号构成的串是句型(sentential form)
- 以 S 为开始符号的 CFG 构成的语言:
语法树
- 根节点是开始符号
- 内部节点是非终止符号
- 叶子节点是终止符号或者
- 如果节点 A 有子节点
- 最终的叶子节点连起来就是一个句子
- 不同的推导会得到不同的树,但是可能会有相同的结果。
最左推导(LeftMost Derivation 前缀推导)
- 总是对句型中最左侧的非终止符号进行一次推导
- 从开始符号推导到结果,被称为 Top-down
最右推导(RightMost Derivation)
- 从结果反向推回开始符号,这个过程被称为规约
- 等价于对语法树进行后序遍历的逆过程
- 最右推导的能力比最左推导要强
抽象语法树
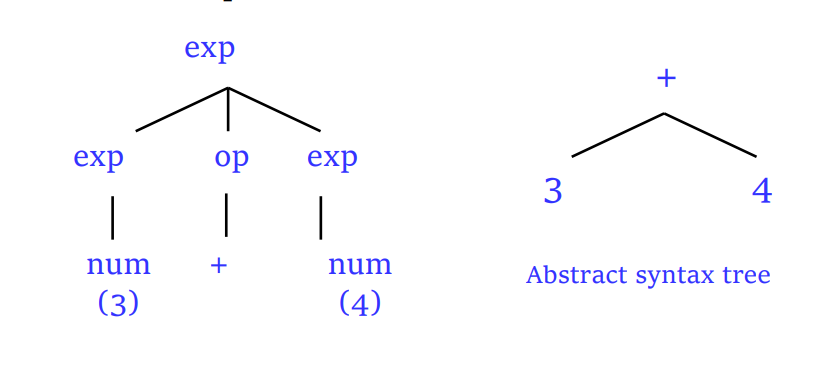
- 比起语法树,省略了部分细节,带来了更好的语法抽象,对于后续编译阶段是一个更好的数据结构
- 它反映了源码 token 序列的一个抽象,比语法树更高效
歧义(Ambiguity)
- 对于一个 CFG,同样的输入可能有不同的解析
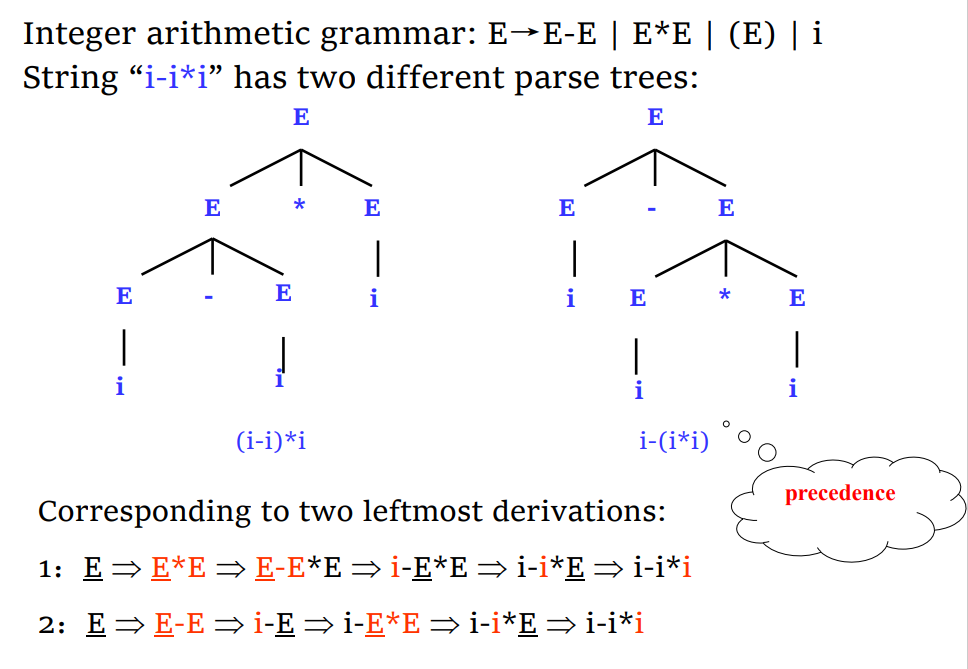
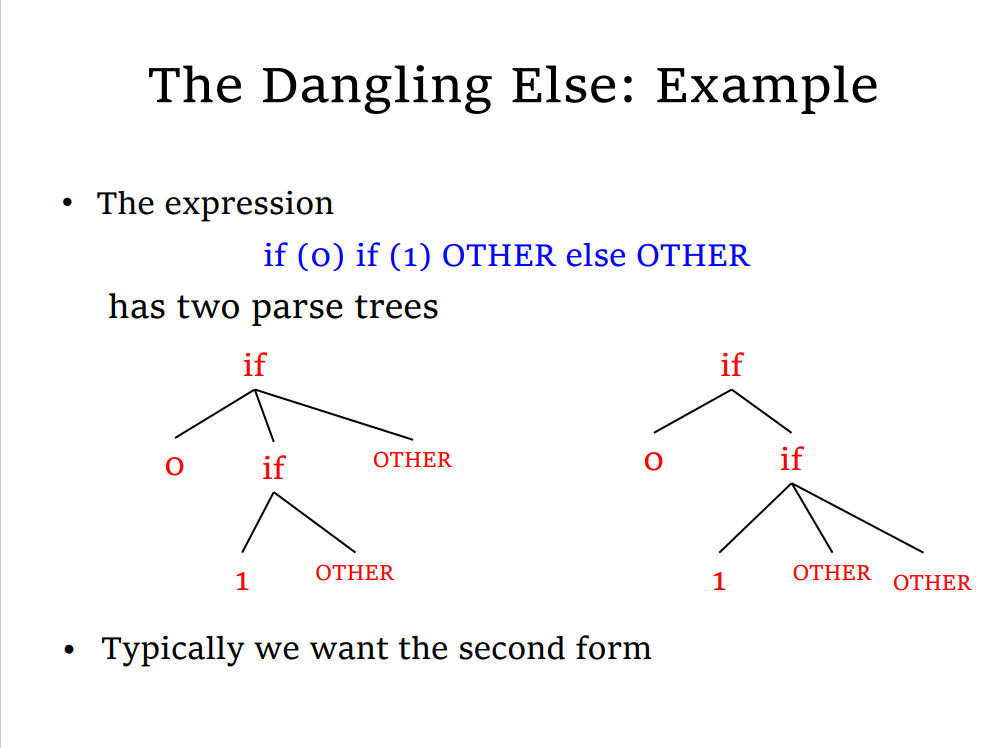
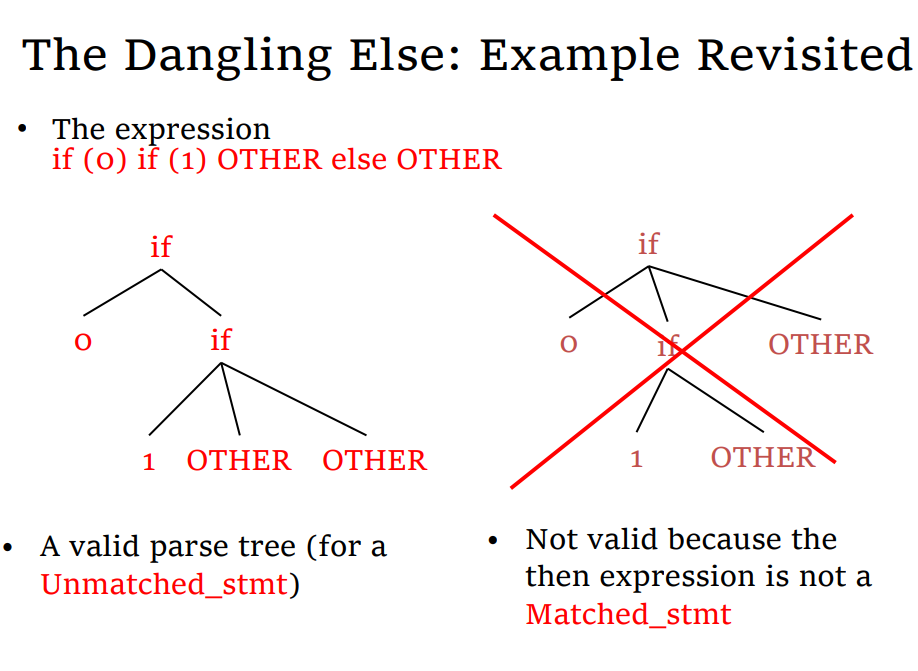
解决方法
- 消除歧义(Disambiguity rule):不改变文法,列举所有可能造成歧义的情况并进行消除,不现实的
- 文法重写:改变文法,进行同义转换:(添加优先级,添加关联性)

语法分析算法(parsing)
Top-Down(Leftmost) parsing
- 本质上是一个图搜索问题,在树上搜索,查找能否获得一个与输入 sentence 匹配的路径
回溯算法(Backtracking)
- 用 BFS:进行图遍历搜索,复杂,时间复杂度过高,产生大量无用分支,时间和空间的最差情况都是指数级别。现代编译器中不被使用
- 剪枝:由终止符号做前缀时,如果无法与输入的前缀匹配则剪枝。(
- 用 DFS:有比 BFS 更好的空间复杂度和时间复杂度,但是无法匹配(
预测推导(predictive parsing)
- Idea:利用先行词(lokkahead tokens),也就是上面提到过的终止符前缀
- 两种分析方法:
- 递归下降分析(Recursive-descent parsing)
- LL(1)分析
预测分析的概念
- 从输入串和文法的开始符号开始分析
- 可以从当前输入的 token(s)唯一确定下一个要使用的产生式
- 预测分析文法包括 LL(k)文法,其中 L 表示从左向右扫描,L 表示最左推导,k 表示“需要
- LL(1)文法是常用的,也不完全常用
Lookahead Sets
First Sets(具体计算看讲义和书)
- 定义
- 计算
%E8%AE%A1%E7%AE%973-BYKQtFqt.png)
%E8%AE%A1%E7%AE%974-Cs3bMHxu.png)
%E8%AE%A1%E7%AE%975-BzGTTr9D.png)
//Todo 提取简练课程笔记
Follow Sets
- 定义:
- 计算:
%E8%AE%A1%E7%AE%972-DtXJaXRD.png)
可空的非终止符(nullable nonterminal)
- 定义:
- 计算:

判定 LL(1)文法
- 计算每个可空的非终止符
- 计算产生式右侧所有的
- 计算(1)中算出的非终止符的
%E7%A4%BA%E4%BE%8B-BVE6NbWu.png)
非 LL(1)到 LL(1)
- 两种简单的非 LL(1)情形:
- 左因子,例如
- 左递归,包括直接左递归和间接左递归,例如
- 要注意:将这两者进行改写后并不能保证改写后的文法是 LL(1),仍需要再进行验证
递归下降
输入
- 非终止符号递归调用,终止符号匹配
int main(){
Token token = getNextToken();
S();/*S is the start symbol*/
if(token!='$') throw error;
}
void A(){
/*select a production of A:A→X_1X_2...X_k*/
for(int i=0; i<k; k++){
if(X[i].isnonterminal()) X[i]();
else if(X[i]==input token) getNextToken();
else throw error;
}
}- 如果
void U(){
if (token in First(x_1)) x_1();
else if (token in First(x_2)) x_2();
...
else if (token in First(x_n))x_n();
else throw error;
}- 如果
void U(){
if(token in First(x_n))x_n();
else throw error;
}改写为:
void U(){
if (token in First(x_n))x_n();
else if(token not in Follow(x_n)) throw error;
}示例





输出(生成语法树)
- 语法树是一个中间表示
- 生成抽象语法树需要定义一个语义规则
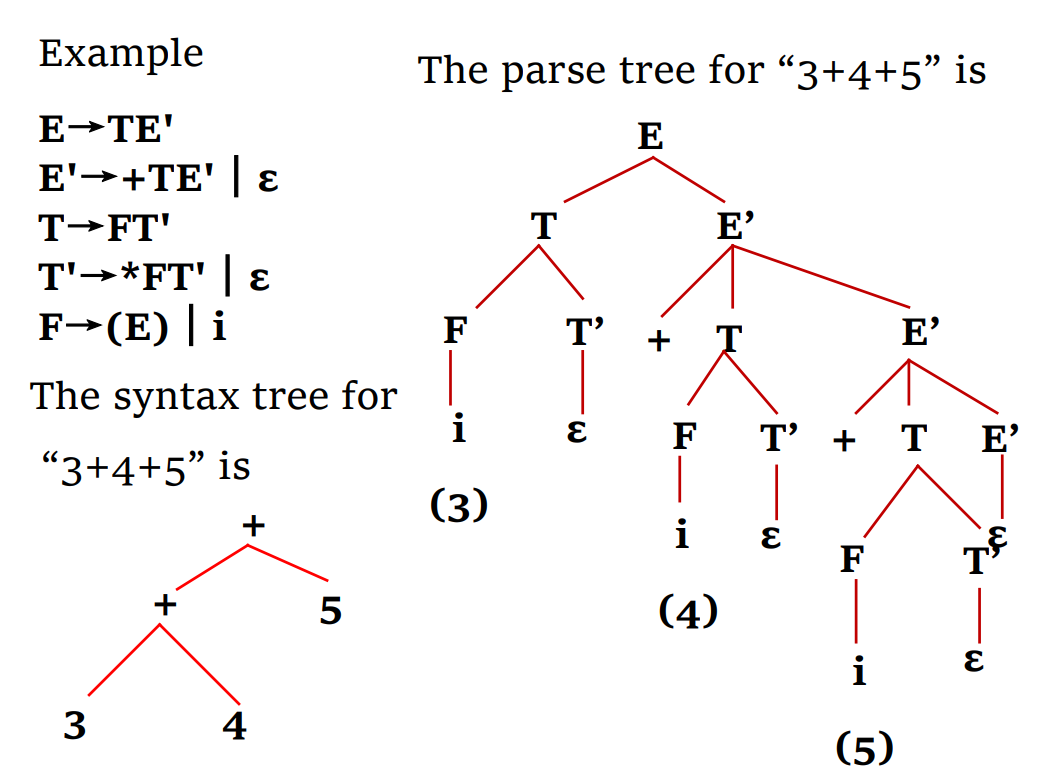


优劣
- 优点:多功能,功能强大,简单有效;灵活,允许程序员安排操作,适用于手工生成的分析器
- 缺点:必须小心安排每个代码里的操作,而且递归操作会带来大量的时间复杂度和空间复杂度。
LL(1)
- 就是在递归下降的基础上用栈代替了递归,时间复杂度为
%E5%8E%9F%E7%90%86-B83M1nOq.png)
- 通过分析表(parsing table)来分析怎么转化一个非终止符号(如果不满足 LL(1)文法,就会出现一个表项里有多个产生式)
产生分析表
- 分析表项
- 构造分析表,对每个产生式
- 如果
_parsing_table1-CxvOlT1V.png)
_parsing_table2-Bt2-2Cu2.png)
- 从分析表的角度来说,一个不满足 LL(1)文法的 CFG 文法产生的产生表的一个表项内可能有多个产生式,无法做到唯一选择
分析步骤
- 开始于把起始符号压入栈中;
- 把栈顶的非终止符号 A 用查表得到的产生式
- 当栈顶元素为终止符号后,将栈顶元素与输入匹配,匹配成功后,同时丢弃栈顶元素和输入元素
- 重复 2、3 步,直到输入和栈同时为空,则分析成功结束。
- 具体流程图(包括错误出现):
%E6%B5%81%E7%A8%8B%E5%9B%BE-Bx56MMvy.png)
- 示例:
%E4%B8%BE%E4%BE%8B-Dba7hb4D.png)
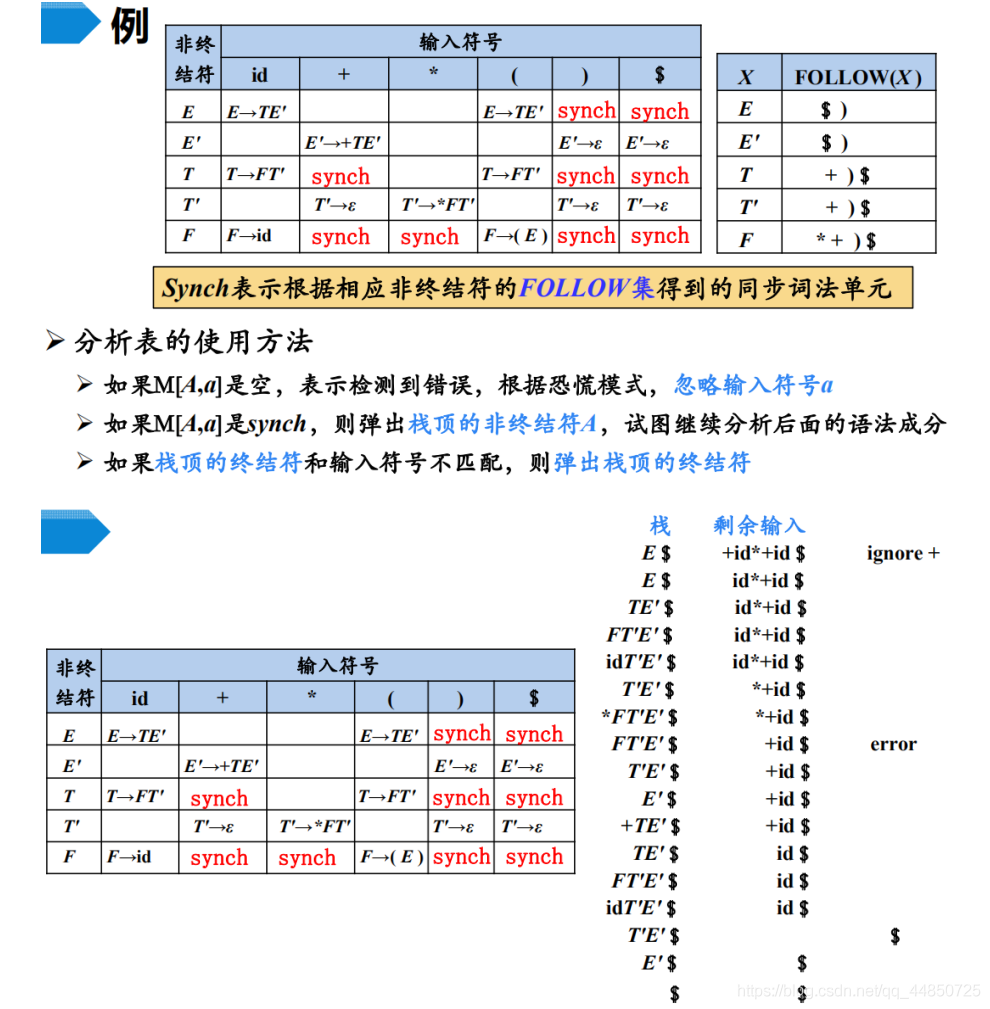
错误处理
- 错误恢复(recovery),在遇到错误时先恢复,让整个分析完成后再一起报错,而不是遇到一个报一个
- 错误修复(repair):在出错后尝试修复
错误恢复
Panic Mode
- 不断尝试可能的 token,如果能使得错误消失,那么就能继续分析了
- 通常从错误部分上下文的


Bottom-up Parsing I
目录
- Handle
- Shift/Reduce Parsing (Where to find handles)
- LR parser
- LR(0) items and LR(0) Parsing Table (How to search for possible handles )
Handle
- 什么时候看到一个什么产生式的右部进行怎么样的规约(用哪个产生式)是 Bottom-up 算法的核心,而这个被归约的部分被称为 handle,例如
- 从输入区移入语法分析栈(workarea)的过程称为 shift,将栈中部分弹出并规约再入栈称为 reduce
- 右句型(tight sentential Form):
Shift and Reduce Parsing
- 把分析栈成文右句型的可行前缀(viable prefix)
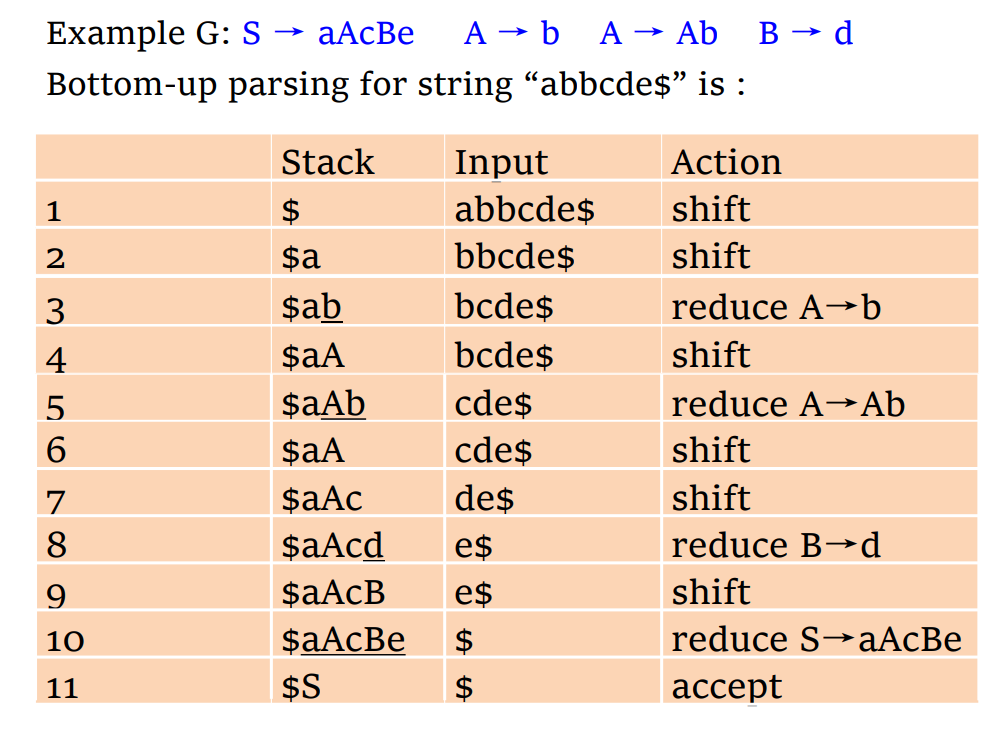
- 这种方法也被称为 LR(0),因为不需要 lookahead token
- 但是 LR 算法需要看到栈顶以下多个元素,因此需要引入 state 来标记
LR Parsing
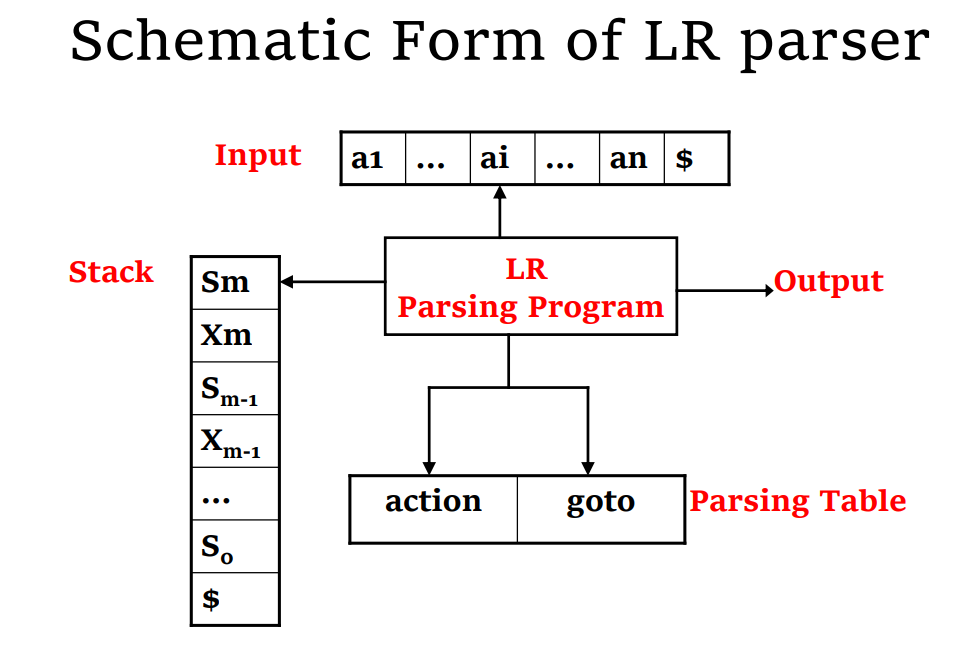
- 其中
Parsing Table
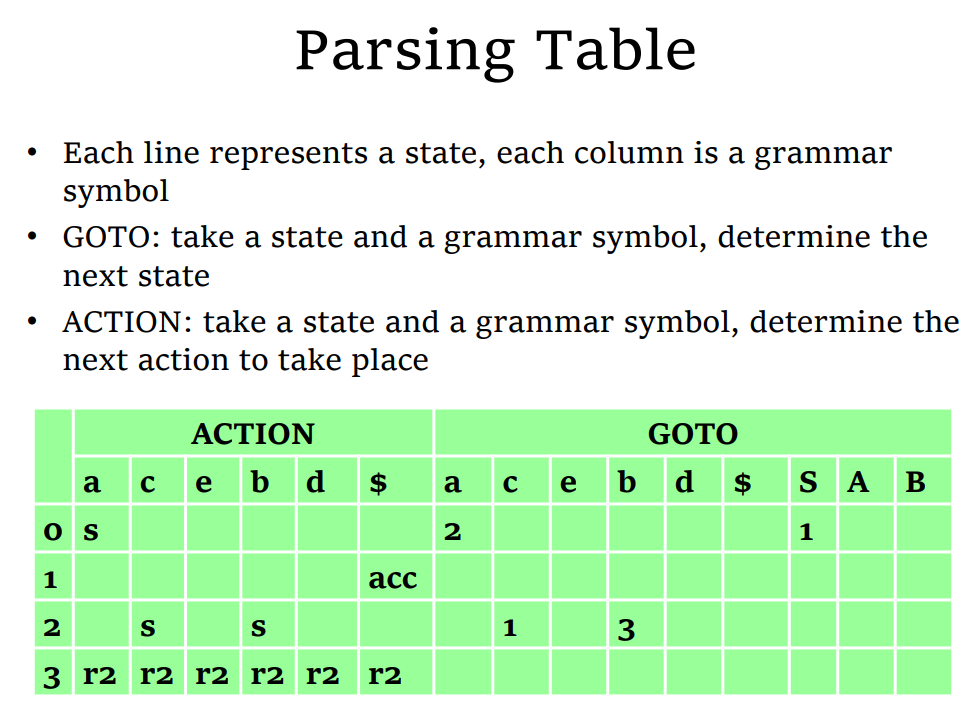
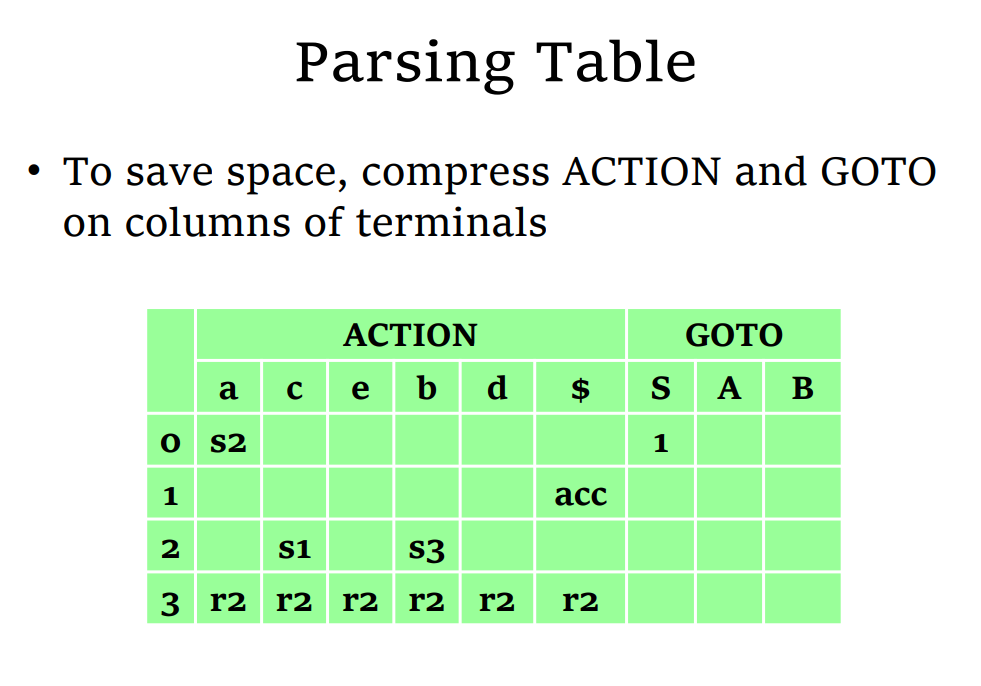
- 对表项
- Shift(
- Reduction(
- 把
- 把非终止符号 A 入栈
- 把状态
- 把
- Shift(
- Accept:表示分析顺利结束
- Error:表示分析遇到了某些问题
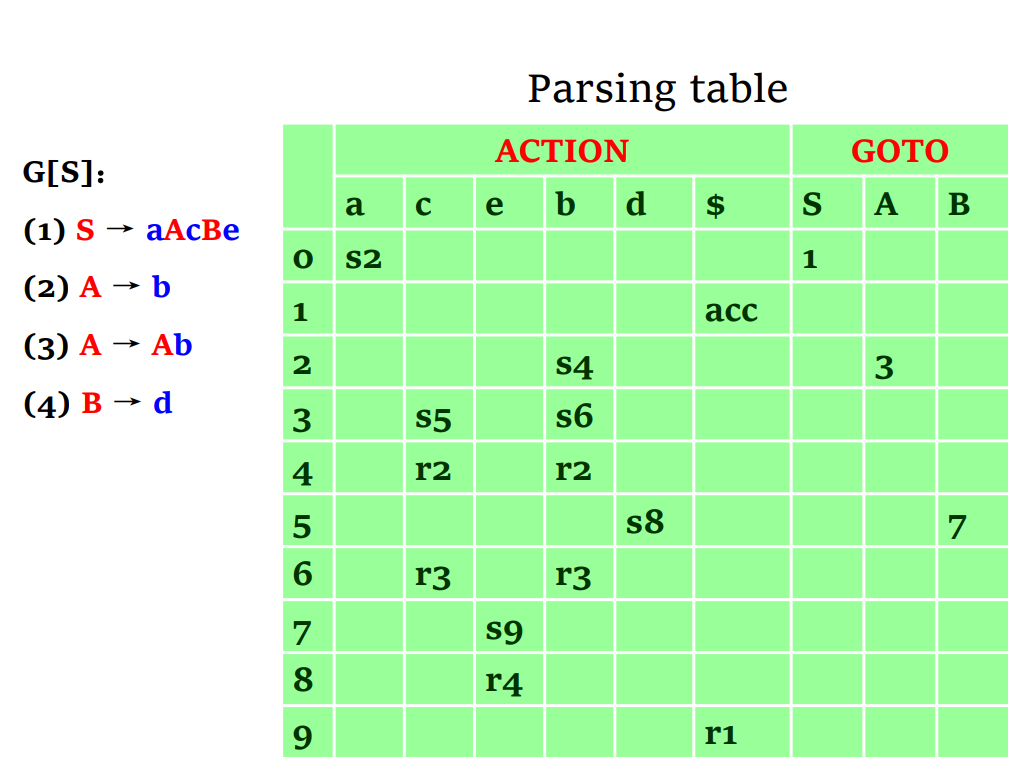
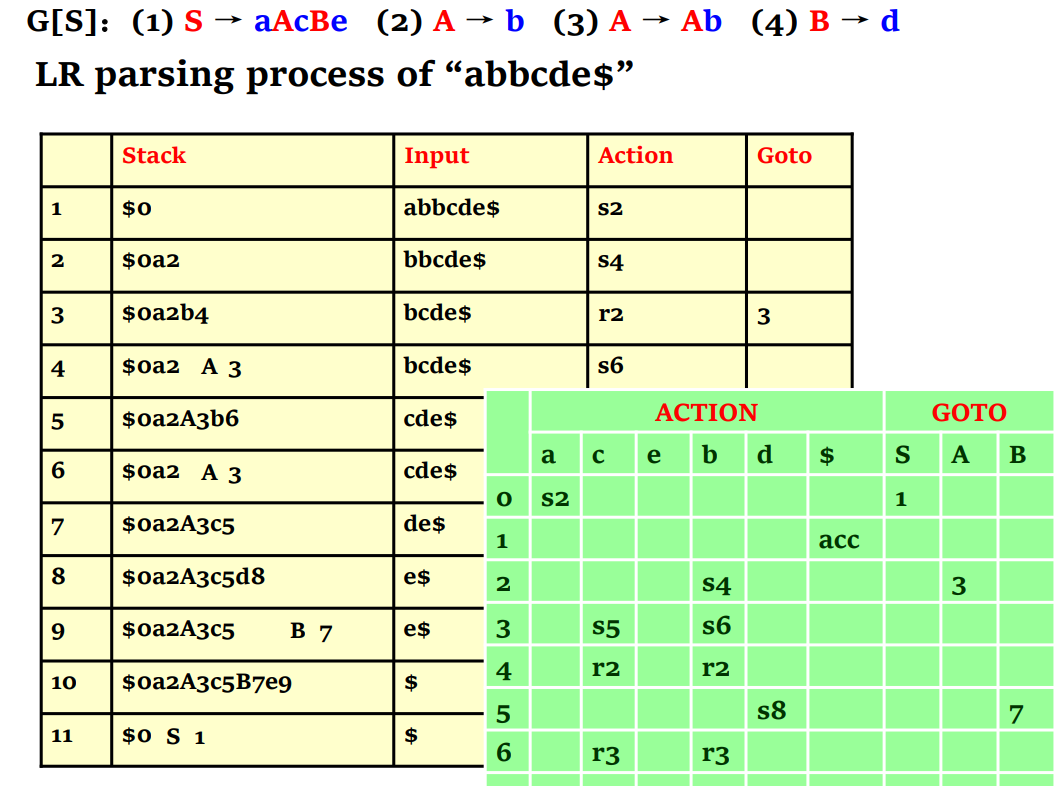
LR(0) items and parsing table
LR(0) items
- 一个语法 G 的 LR(0)项就是 G 的产生式再在其右侧加上一个位置点
- 例如
Items 的自动机形式
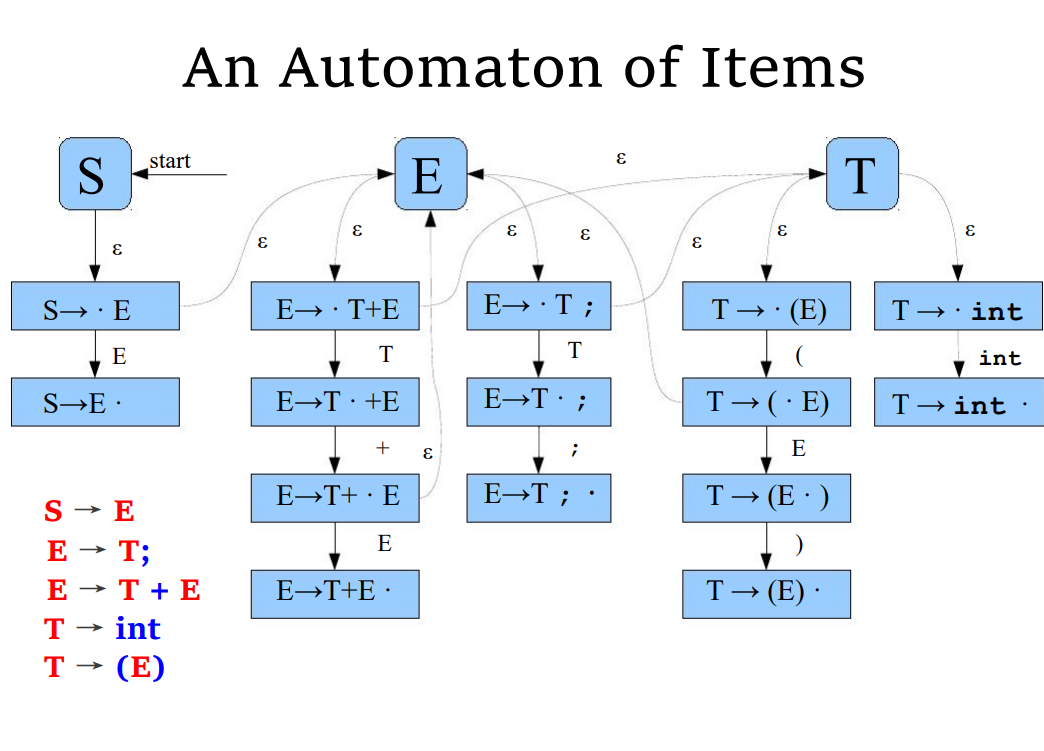
构建 NFA
- 每个状态是一个项
- 几乎用不上 不用了解
构建 DFA
- 每个状态是一个项集
- 增广(augment):如果原来的文法的开始符号没有做为一个产生式的右部,就新增一个产生式
- 构建开始状态:把每个产生式都加入初始状态
- 构造转移:对项集中的每个项,看输入符号后位置点会不会后移,是的话就构造一个转移和对应的项集,并把其
- 不断重复 2,3,把增广产生式存在的项集作为接受状态
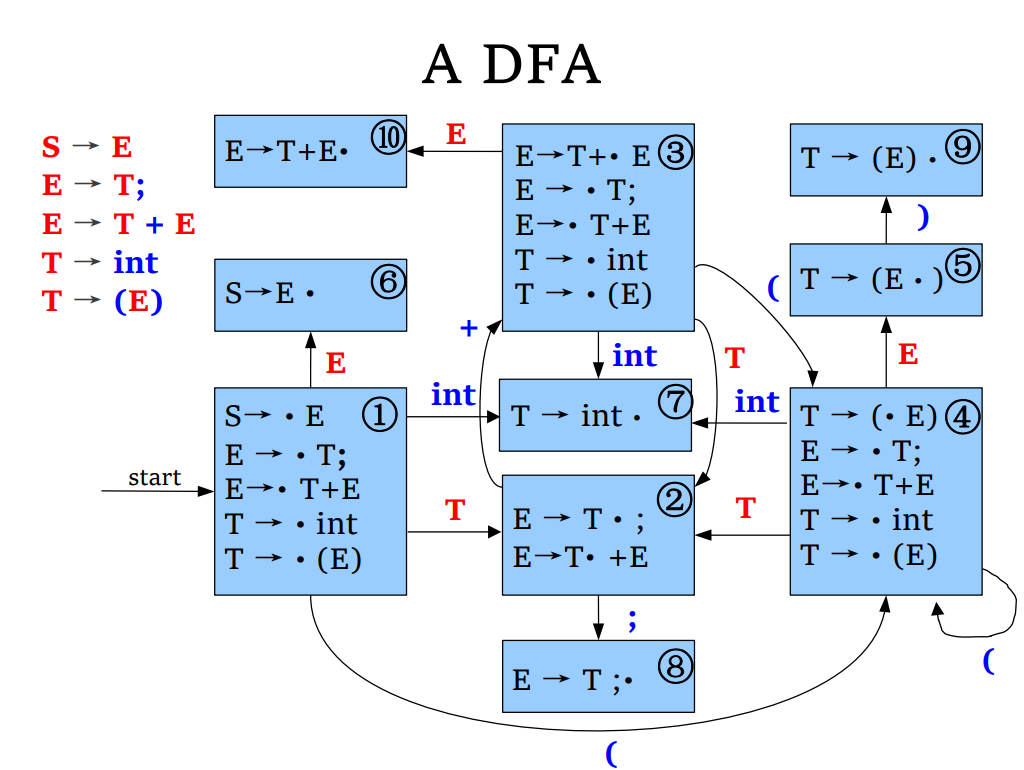
构建 LR(0) Parsing Table
- 构建 DFA
- 构建 state K 对应的 ACTION:如果
LR(0)的限制
- LR(0)的自动机中有完成项的项集只能有完成项,否则会出现 shift/reduce 冲突(同时有完成项和非完成项)或 reduce/reduce 冲突(有多个完成项)
Bottom-UP Parsing II
目录
- SLR(1)
- LALR(1)
- LR(1)
SLR(1)(Simple LR(1))
SLR(1)文法
- simple 在使用的仍然是 LR(0)的 DFA
%E8%AF%AD%E6%B3%95-BLVkqArD.png)
对于一个状态
- 如果
- 如果
- 如果
- 否则报错
SLR(1)分析表
%E5%88%86%E6%9E%90%E8%A1%A8-CxDn4AIH.png)
SLR(1)算法
//Todo 插入
SLR(1)的缺点
- 只关注 FOLLOW set,在某些情况下不能正确规约。原因是 Follow(A)表示某个非终止符号所有可能跟着的符号,而并不是在每个包含 A 的句型中都会出现 Follow(A)中的符号,我们用 Follow(A)进行规约的时候就会出现这种问题
%E7%9A%84%E7%BC%BA%E7%82%B9-B9vn4Hnr.png)
LR(1)
LR(1)的项
LR(1)的项由 LR(0)的项(被称为核 core)和一个 lookahead token 组成
%E9%A1%B9-Cg2q9HWK.png)
所有 LR(0)、LL(1)文法都是 LR(1)文法
所有确定的 CFL(context free language)都有一个 LR(1)文法
所有 LL(k)、LR(k)语言都是 LR(1),尽管某个语言中的某个文法可能不是 LR(1)
LALR(1)
- 把有相同的核,不同 lookahead token 的项进行合并,但是包含的语义和 LR(1)是不一样的,可能并不等价
- LR(0)、SLR(1)和大多数 LR(1)都是 LALR(1)文法,