
Chapter2 词法分析
大纲
- 扫描过程 Scanning Process
- 正则表达式 Regular Expressions
- 有限自动机 Finite Automata(NFA(nondeterministic 非确定性有限自动机) and DFA(deterministic 确定性))
- RE 转换 NFA(McNaughton-Yamda-Thompson algorithm)
- NFA 转换 DFA(子集算法 Subset construction Algorithm)
- 最小化 DFA(State-Minimization Algorithm)
扫描过程
while(137<n)
++i;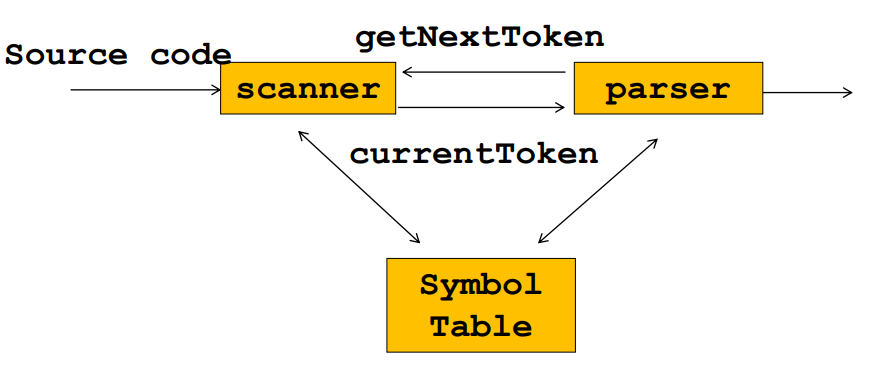
词元(tokens)
- 一个 token 表示源代码中的一个逻辑语义片段,可以是一个关键字、一个变量名,以
- token 表示一组符合特定规则的字符,例如标识符必须以字母开头并只包含字母和数字
- 每个 token 关联一个词素(lexeme)
- lexeme 即为 token 的字面值,如“137”,”int“等
- 每个 token 可能有属性(attributes)
- 从字面值中得到的额外信息,一般是一个数值,如
- 从字面值中得到的额外信息,一般是一个数值,如
正则表达式
形式化语言
字符表(alphabet)
是指一个由符号(字符、数字、特殊符号)组成的有限集,例如
字符串(string)
- 一个基于某个字符表的字符串是一个由字符表中给出的符号组成的有穷序列
- 特殊的
- 例如
- 0,00,10 是
- a,ab,aaca 是
- 0,00,10 是
语言(language)
- 由基于某一给定的字符表的一系列字符串组成的集合
语言的运算
正则表达式
原子表达式
- 字符表中的符号 a 只匹配 a
复合表达式
假设
- (R)可以提高运算优先级(
例子
- 中间包含 00 的任意串:
- 包含最多一个零:
- 标识符:
有限自动机
概念
- 正则表达式可以用一个有限自动机来实现
- 有两种类型的有限自动机——NFA 与 DFA
- 核心思想
有限自动机的数学定义
是一个五元组(tuple)
NFA(Nondeterministic Finite Automata)
- 对于给定的状态,一个输入会有多个转移
- 可以有
NFA 的执行
- 维护一个下一状态的集合,初始为空
- 对于每个当前状态,执行
- 对于当前输入执行全部转移
- 将所有转移的结果加入下一状态的集合中
- 再将所有
时间复杂度
- 对一个长为
DFA(Deterministic Finite Automate)
- 每个状态每个输入只会有一个转移
- 没有
DFA 的执行
int kTransitionTable[kNumStates][kNumSymbols]={
{2,1,3,0,0,3}
};
bool kAcceptTable[knumStates] = {
true,
true,
false ...
}
bool simulateDFA(string input){
int state = 0
for(char ch: input)
state = kTransitionTable[state][ch];
return kAcceptTable[state];
}时间复杂度
- 对于任意复杂的自动机,都有
RE 到 NFA
McNaughton-Yamada-Thompson 算法
算法
- 将 RE 分为连续的子表达式(subexpression),每个括号内表示一个子表达式,可以用一个一般树来描述,越靠近根节点运算优先级越低
- 构建起基本子表达式的 NFA
- 再将构建起来的 NFA 结合起来,形成最终的 NFA
基本子表达式的 NFA
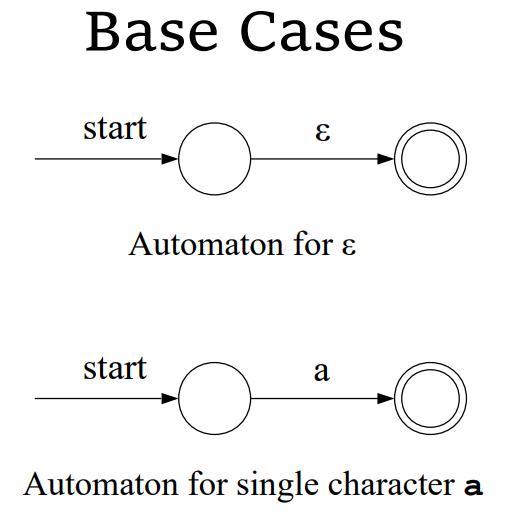
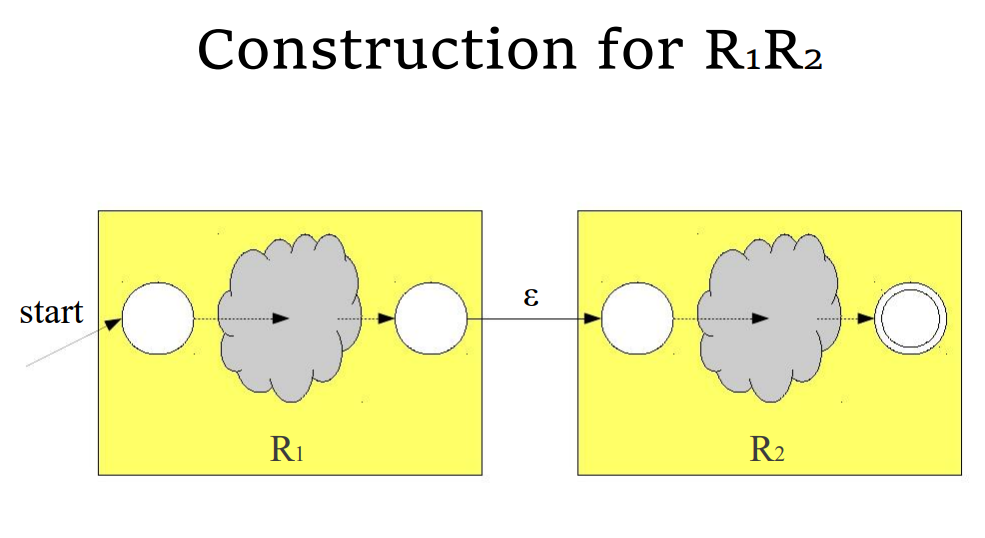
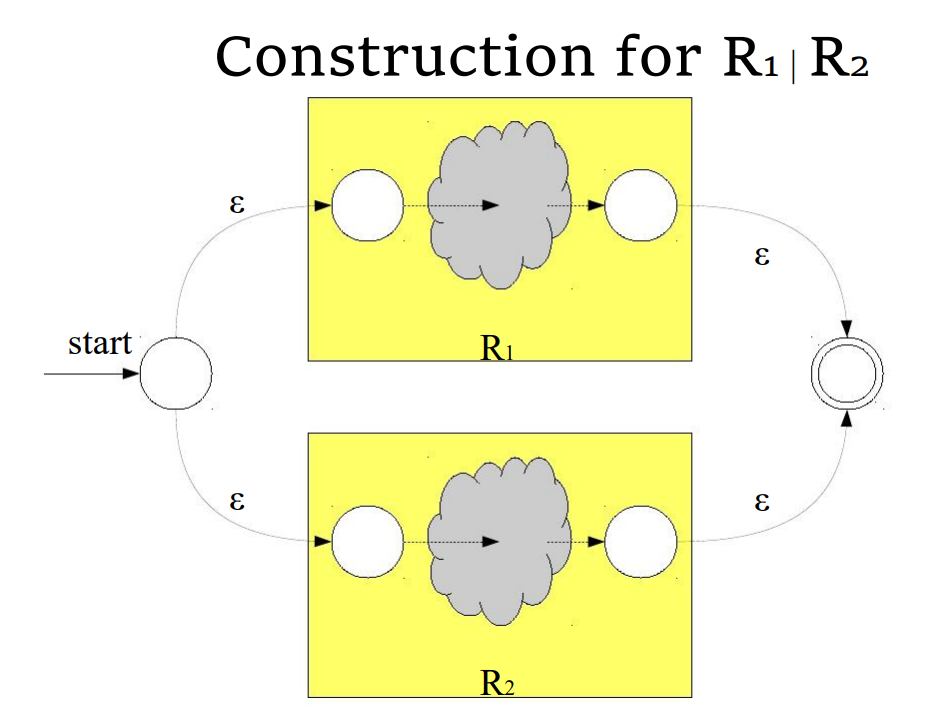
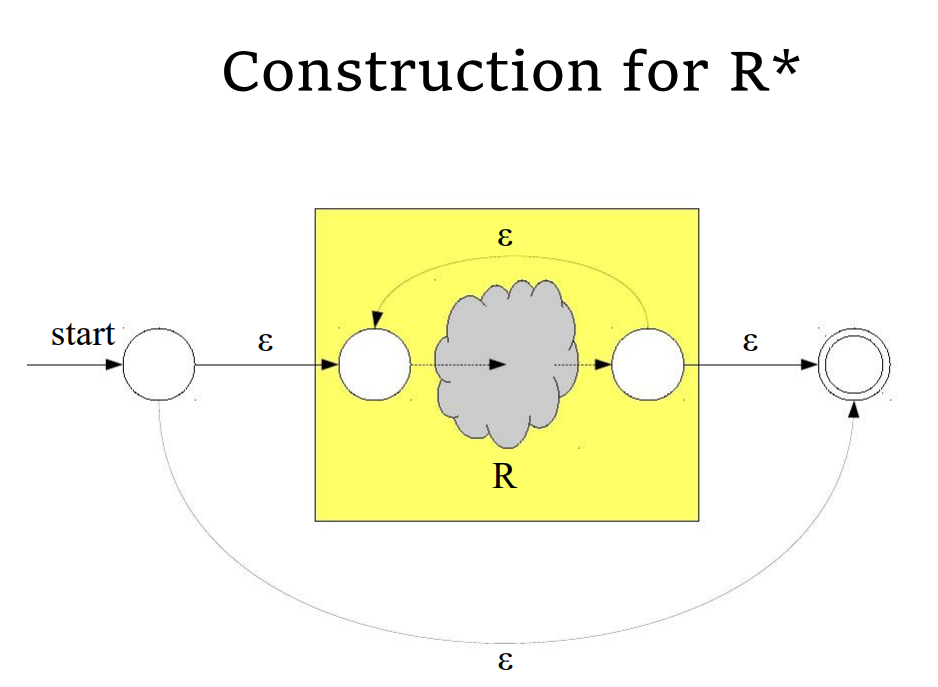
- 对于一个长度为
特点
- 只有一个接收态
- 接收态没有出变迁(没有出边)
- 初始状态没有入变迁(没有入边)
冲突解决
- 最长子串(Maximal munch):尽可能识别更长的子串
- 优先级系统(priority system 硬编码):给不同的 token 设置不同的优先级
NFA 到 DFA
- move 方法:
- 子集构造法:
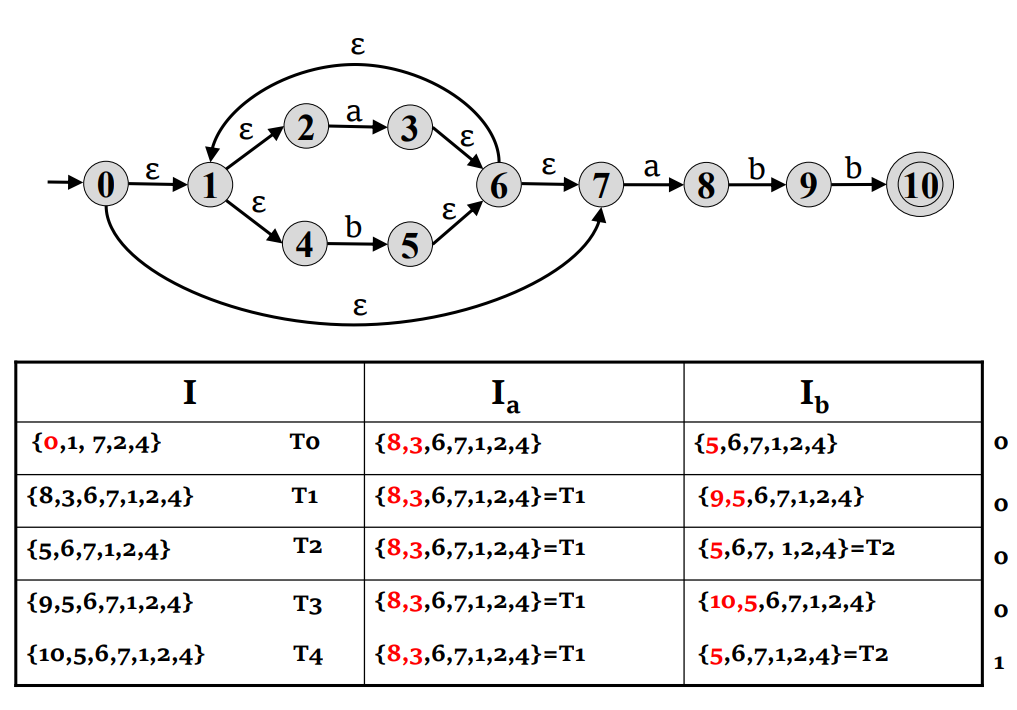
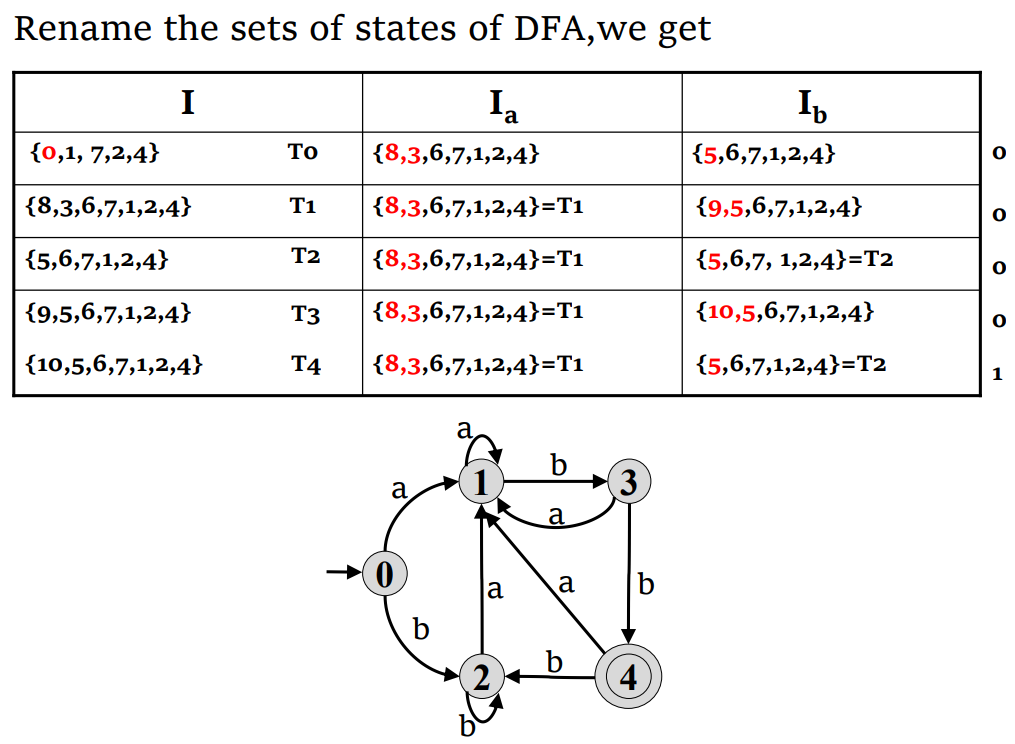
子集构造算法
- 计算
- 对于这个集合以及每个后续集合 S ,我们计算每个字符
- 不断进行这个过程,直到没有新的状态和转换生成
- 标记包含接受态的状态
最小化 DFA
- 等价状态:对于两个状态
Hopcroft 算法
- 将 DFA 中的状态划分为两个等价类:接受状态和非接受状态。
- 对于每个等价类,根据输入字符的转移关系。如果对于某个字符使得一个等价类内的一个状态转移到另一个等价类中的状态,就将这个状态其进一步划分为更小的等价类。
- 重复第 2 步,直到不能再划分为止。
//基于等价类的思想
split(S)
foreach(character c)
if(c can split s)
split s into S1, S2
//分别表示未迁出的状态集合和迁出的状态集合
hopcroft()
split all nodes into N, A
while(set is still changes)
split(s)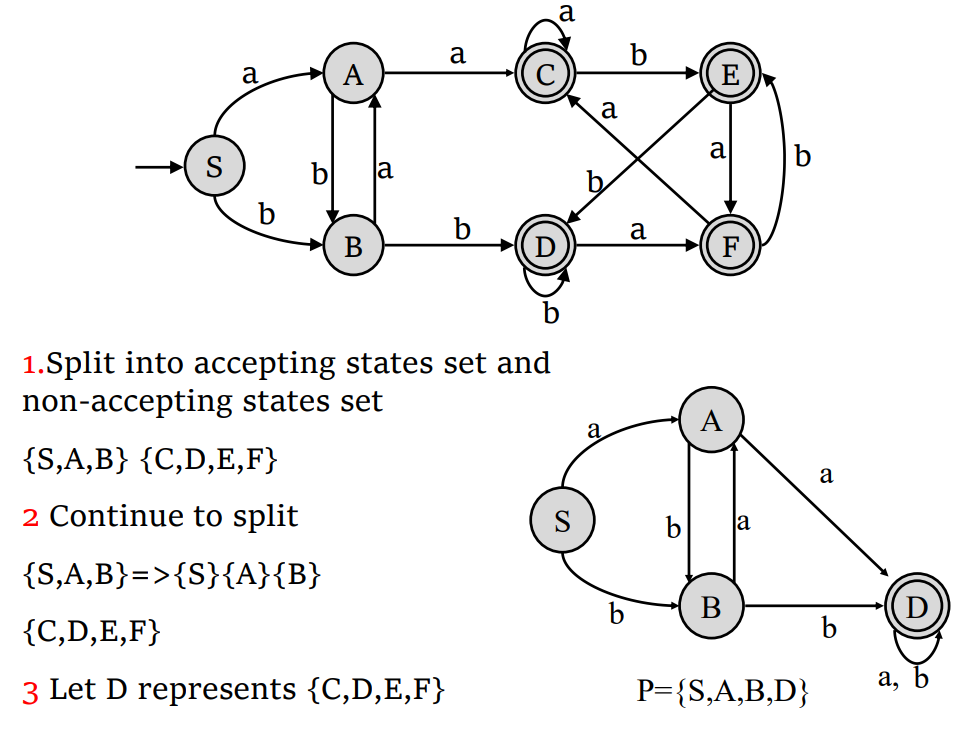
- 不过一般做题直接颅内找等价就行了,不用一定按照这个划分一步步做下去。