
基于锁的协议(Lock-Based Protocols)
- 锁是一种控制对数据项并发访问的机制。
- 数据项可以以两种模式进行锁定:
- 独占(X)模式:数据项既可以读取也可以写入。使用 lock-X 指令请求 X 锁。
- 共享(S)模式:数据项只能读取。使用 lock-S 指令请求 S 锁。
- 锁请求发送给并发控制管理器。只有在请求被授予后,事务才能继续进行。

- 上述方式的锁操作不能足够保证可串行化性
- 如果在读取 A 和 B 之间对它们进行了更新,显示的总和将是错误的。
- 锁协议是所有事务在请求和释放锁时遵循的一组规则。锁协议限制了可能的调度集合。
锁兼容性矩阵
| S | X | |
|---|---|---|
| S | true | false |
| X | false | false |
- 如果请求的锁与其他事务已经持有的锁在数据项上兼容,那么可以向事务授予对该数据项的锁。
- 如果无法授予锁,请求的事务将被要求等待,直到其他事务持有的所有不兼容的锁都被释放。
- 然后,锁将被授予该事务。
基于锁的协议的陷阱(Pitfalls of Lock-Based Protocols)
死锁(deadlock)
考虑以下部分调度: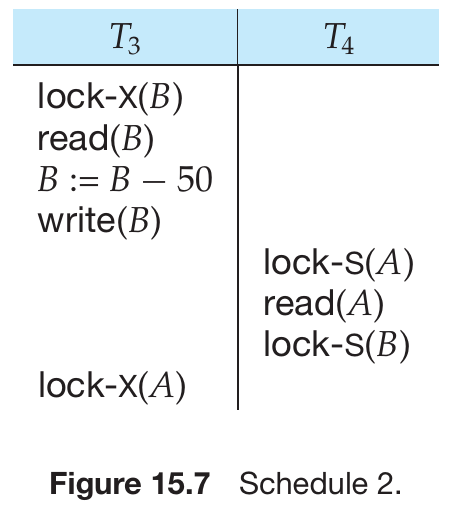
- T3 和 T4 都无法进行进一步的操作 - 执行 lock-S(B)导致 T4 等待 T3 释放对 B 的锁,而执行 lock-X(A)导致 T3 等待 T4 释放对 A 的锁。
- 这种情况被称为
死锁(deadlock)。 - 为了处理死锁,必须回滚 T3 或 T4 之一,并释放其持有的锁。
- 大多数锁协议存在死锁的潜在风险。死锁是一种必要的弊端。
饥饿(Starvation)
- 如果并发控制管理器设计不良,也可能发生
饥饿(Starvation)现象。例如:- T1 请求 L-S(Q);
- T2 请求 L-X(Q);
- T3 请求 L-S(Q);
- T4 请求 L-S(Q);
- T5 请求 L-S(Q);
- T6 请求 L-S(Q);
- ...如果 T3、T4、T5、T6 被授予 S 锁,那么 T2 将被饿死(无法获得锁)。
- 一个事务可能在等待对某个项的 X 锁,而一系列其他事务请求并被授予对同一项的 S 锁。
- 由于死锁,同一个事务可能被多次回滚。
- 并发控制管理器可以设计成防止饥饿现象。
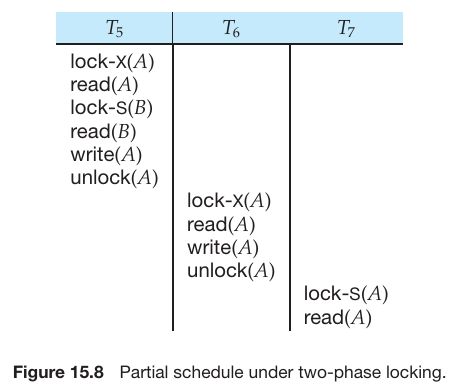
两阶段锁协议(The Two-Phase Locking Protocol)
- 这是一种确保冲突可串行化调度的协议。
- 第一阶段:增长阶段
- 事务可以获取锁。
- 事务不可以释放锁。
- 第二阶段:缩减阶段
- 事务可以释放锁。
- 事务不可以获取锁。
- 第一阶段:增长阶段
- 两阶段锁定协议确保可串行化。可以证明,事务可以按照其锁点(即事务获得最终锁的点)的顺序进行序列化。
优缺点与改进
- 优点:确保可串化
- 缺点:可能有死锁和级联回滚
- 改进:
- 改进 1:严格的两阶段锁定(strict two-phase locking)。在这种协议中,事务必须保持其所有独占锁直到提交/中止。
- 改进 2:强两阶段锁定(Rigorous two-phase locking)更加严格:在这里,所有的锁都保持到提交/中止。在这个协议中,事务可以按照提交的顺序进行串行化。
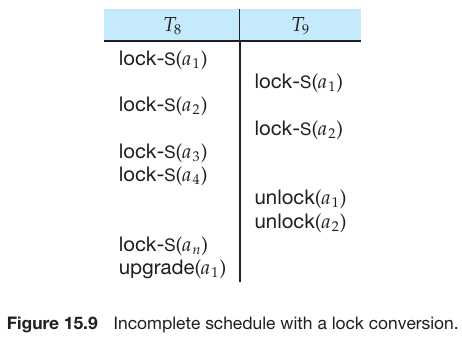
具有锁转换(Lock Conversions)的两阶段锁定
- 第一阶段:
- 可以获取数据项的锁-S。
- 可以获取数据项的锁-X。
- 可以将锁-S 转换为锁-X(升级)。
- 第二阶段:
- 可以释放锁-S。
- 可以释放锁-X。
- 可以将锁-X 转换为锁-S(降级)。
- 这个协议确保了可串行化。但仍然依赖于程序员插入各种锁定指令。
锁表(Lock Table)
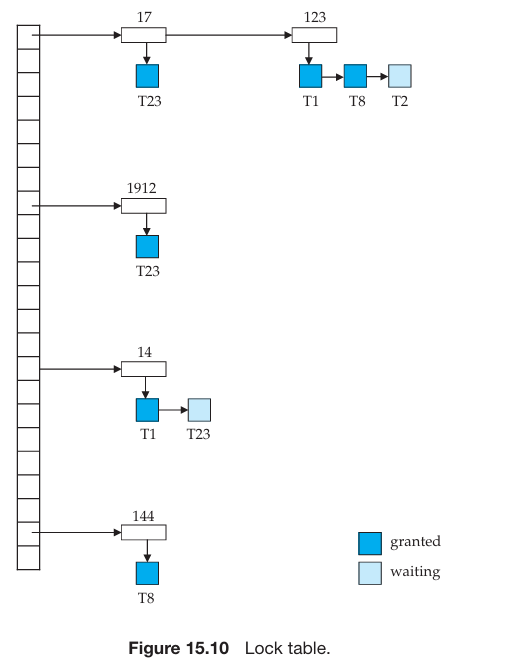
- 对于当前锁定的每个数据项,它维护一个记录链表,每个请求对应一个记录,按照请求到达的顺序排列。它使用一个以数据项名称为索引的哈希表来查找数据项的链接列表(如果有);该表称为
锁表(Lock Table)。数据项链表的每条记录都记录了哪个事务发出了请求,以及它请求的锁定模式。
基于图的协议(Graph-Based Protocols)
基于图的协议是两阶段锁定的一种替代方案。
- 对所有数据项集合
- 如果
- 这意味着集合
- 如果
树协议(Tree Protocol)
- 树协议是图协议的一种简单类型。
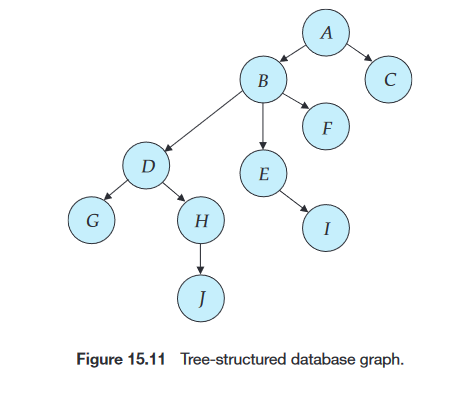
- 只允许独占锁(lock-X)。
- 数据项可以在任何时候解锁。
- 已被
优缺点
优点:
- 树协议确保了冲突可串行化,同时避免了死锁。
- 在树锁定协议中,解锁可能比两阶段锁定协议更早发生。
- 等待时间较短,增加并发性。
- 协议无死锁,不需要回滚操作。
缺点:
- 协议不能保证可恢复性或级联自由。
- 需要引入提交依赖性以确保可恢复性。
- 事务可能需要锁定其不访问的数据项。
- 增加了锁定开销和额外的等待时间。
- 可能降低并发性。
- 在两阶段锁定下不可能的调度在树协议下可能实现,反之亦然。
| 协议名 | conflict serializable | NO deadlock | Recoverability | cascadelessness |
|---|---|---|---|---|
| Two-Phase Locking Protocol | Y | N | N | N |
| strict Two-Phase Locking Protocol | Y | N | Y | Y |
| Rigorous Two-Phase Locking Protocol | Y | N | Y | Y |
| Tree Protocols | Y | Y | N | N |
死锁处理(Deadlock Handling)
- 如果存在一组事务,并且该组中的每个事务都在等待该组中的另一个事务,则系统将发生死锁。
- 对待死锁的 2 种策略:
- 预防, 使得死锁不出现(Deadlock prevention)
- 允许出现死锁, 然后解锁. 检测+恢复.
策略 1:死锁处理
- 如果存在一组事务,其中每个事务都在等待该组中的另一个事务,那么系统就处于死锁状态。
- 死锁预防协议确保系统永远不会进入死锁状态。一些预防策略包括:
- 预防策略 1:要求每个事务在开始执行之前锁定其所有数据项(预声明)。
- 预防策略 2:对所有数据项强制部分排序,并要求事务只能按照部分排序指定的顺序锁定数据项(基于图的协议)。
- 以下方案仅出于死锁预防的目的使用事务时间戳。
- 预防策略 3:等待-死亡方案(wait-die scheme)- 非抢占式(老的等,新的死)
- 较旧的事务可能等待较新的事务释放数据项。较新的事务永远不会等待较旧的事务;相反,它们会被回滚。
- 一个事务可能在获取所需的数据项之前多次回滚。
- 预防策略 4:伤害-等待方案(wound-wait scheme)- 抢占式(老的抢,新的等)
- 较旧的事务强制回滚较新的事务,而不是等待它。较新的事务可能等待较旧的事务。
- 可能比等待-死亡方案中的回滚次数少。
- 预防策略 3:等待-死亡方案(wait-die scheme)- 非抢占式(老的等,新的死)
- 在等待-死亡方案和伤害-等待方案中,被回滚的事务会使用其原始时间戳重新启动。因此,较旧的事务优先于较新的事务,从而避免了饥饿(starvation)。
- 预防策略 5:基于超时的方案:
- 事务仅在指定的时间内等待锁。超过该时间后,等待超时,事务被回滚。
- 因此,死锁是不可能发生的。
- 实施简单,但可能会出现饥饿的情况。同时,确定超时间隔的合适值也比较困难。
- 预防策略 5:基于超时的方案:
策略 2:死锁检测
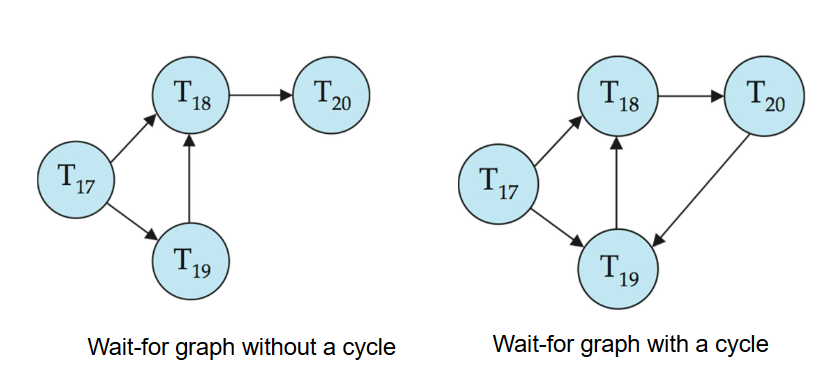
- 死锁可以被描述为一个
等待图(wait-for graph),它由一对
- 图的构造:
- 当
- 判断定理:如果等待图中存在一个循环,那么系统处于死锁状态。必须定期调用死锁检测算法来查找循环。
死锁恢复
- 当检测到死锁时:
- 必须回滚(选择一个牺牲者)某些事务来打破死锁。
- 回滚 - 确定回滚事务的程度:
- 完全回滚:中止事务,然后重新启动它。
- 更有效的方法是仅回滚事务到打破死锁所必需的程度。
- 如果总是选择同一个事务作为牺牲者,则会发生饥饿。为了避免饥饿,在成本因素中包括回滚次数。
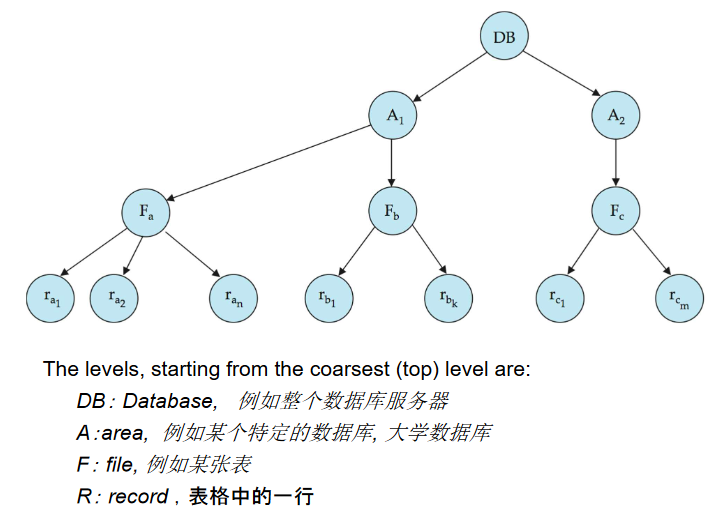
多重粒度(Multiple Granularity)
- 允许数据项具有不同的大小,并定义数据粒度的层次结构,其中小的粒度嵌套在较大的粒度内。
- 可以以图形方式表示为树(但不要与树锁定协议混淆),根据资源的包含关系来确定父子关系。
- 当事务显式锁定树中的一个节点时,它隐式地以相同的模式锁定该节点的所有后代节点。
- 锁定的粒度(在树中进行锁定的层级):
- 细粒度(树的较低层级):高并发性,高锁定开销。
- 粗粒度(树的较高层级):低锁定开销,低并发性。
意向锁定模式(Intention Lock Modes)
略
插入和删除操作
略
弱一致性级别(Weak Levels of Consistency)
- 二级一致性(Degree-two consistency):与两阶段锁定不同之处在于 S 锁可以在任何时候释放,并且可以在任何时候获取锁。
- X 锁必须持有直到事务结束。
- 不能保证串行化,程序员必须确保不会发生错误的数据库状态。
- 游标稳定性(Cursor stability):
- 对于读操作,每个元组被锁定,读取,然后立即释放锁。
- X 锁持有直到事务结束。
- 是二级一致性的特殊情况。
在 SQL 中的弱一致性级别
- SQL 允许非串行化的执行。
- 串行化(Serializable):是默认设置。
- 可重复读(Repeatable read):只允许读取已提交的记录,并且重复读取应返回相同的值(因此应保留读取锁)。
- 然而,并不需要阻止幻影现象
- 事务 T1 可以看到事务 T2 插入的一些记录,但可能看不到 T2 插入的其他记录。
- 然而,并不需要阻止幻影现象
- 读已提交(Read committed):与二级一致性相同,但大多数系统将其实现为游标稳定性。
- 读未提交(Read uncommitted):允许读取未提交的数据。
- 在某些数据库系统中,默认的一致性级别是读已提交。
- 当需要时,必须明确更改为串行化:设置隔离级别为 serializable。