
静态验证(Static Verification)与动态验证(Dynamic Verification)
静态验证是指在不运行程序的情况下对程序进行验证
动态验证是指借助测试用例等方式,通过运行成勋来对程序进行验证,将输入值(input value)输入程序中,将真实输出(actual value)与预期输出(expected value)做比对,来判断程序的正确性
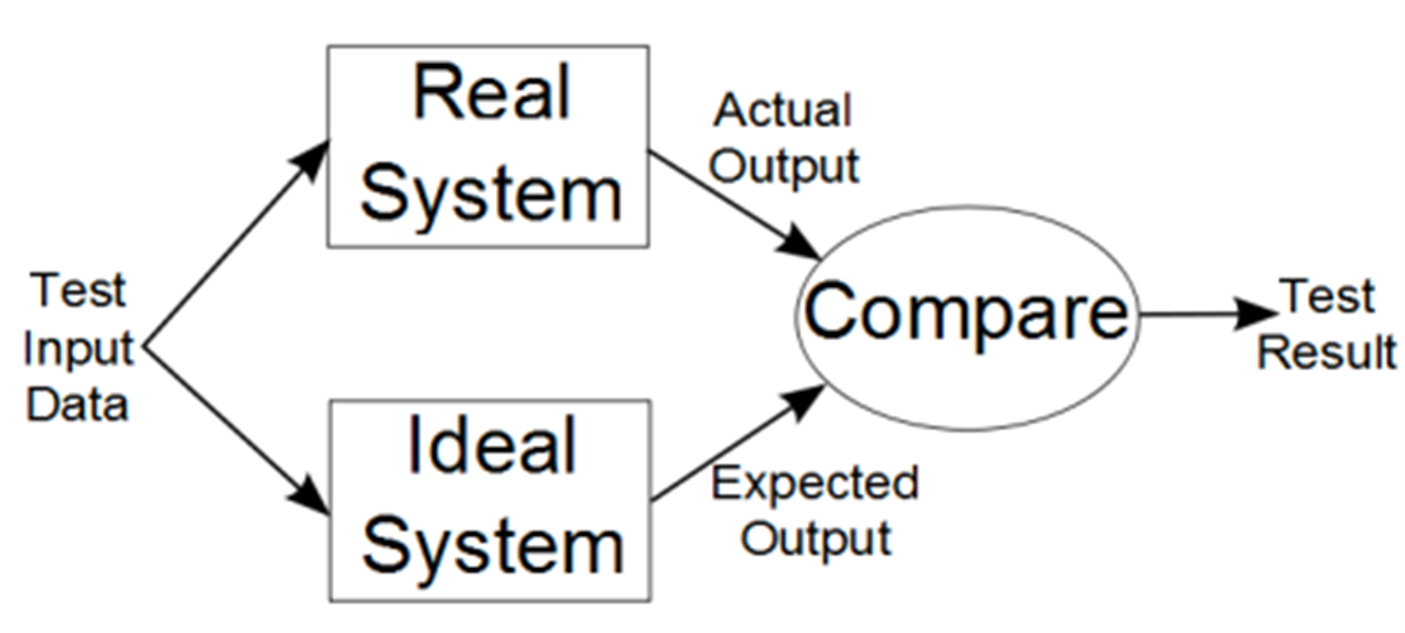
理想系统(ideal system)由规范表示,而真实系统是实际代码。
测试成功并不需要通过结果。 失败的测试也会传授一些关于系统的新知识
黑盒测试(Black Box Testing)与白盒测试(White Box Testing)
- 黑盒测试完全基于程序规范(specification),旨在验证程序是否满足规定的要求
- 白盒测试使用软件的实现来导出测试。 这些测试旨在测试程序代码的某些方面
黑盒测试
- 黑盒测试也称为功能测试、数据驱动测试或基于规范的测试,是从用户角度进行的测试。
- 黑盒测试的主要错误类型有:
- 功能不正确或缺失;
- 接口及接口错误;
- 性能误差;
- 数据结构或外部数据访问错误;
- 初始化或终止条件等错误。
- 每个软件功能必须包含在测试用例或经批准的例外情况中。
- 使用最小的数据类型和数据值集进行测试。
- 使用一系列实际数据类型和数据值来测试过载和其他“最坏情况”结果。
- 使用假设的数据类型和数据值来测试拒绝不规则输入的能力。
- 测试影响性能的关键模块,如基本算法、精度、时间、容量等是否正常。
优点
- 有目的地发现 Bug,更准确地定位 Bug。
- 黑盒测试可以证明产品是否满足用户所需的功能,满足用户的工作要求。
- 黑盒测试与软件本身如何无关实施的。如果实现发生变化,黑盒测试用例仍然存在可用(可重用性,面向回归测试)
- 测试用例开发可以与软件开发同时进行,可以节省软件开发时间。 大多数黑盒测试用例可以通过软件用例来设计。
- 可以重复相同的动作,试验中最枯燥的部分可以由机器完成。
缺点
- 需要充分了解待测试的软件产品所使用的技术,测试人员需要有较多的经验。
- 大量的测试用例
- 测试用例可能会产生大量冗余
- 功能测试覆盖率达不到 100%
- 在测试过程中,很多都是手工测试操作。
- 测试人员负责大量文件和报告的准备和整理。
过程
- 计划阶段(Test plan stage)
- 设计阶段(Test design stage):根据程序需求说明书或用户手册,按照一定的标准化方法划分软件功能并设计测试用例
- 测试执行阶段(Test execution stage):
根据设计的测试用例执行测试;
免费测试(作为测试用例测试的补充) - 测试总结阶段(Test summary stage)
测试用例(Test case)
- 测试用例是描述输入、操作或时间以及期望结果的文档。 其目的是确定应用程序的某个功能是否正常工作。
- 软件测试用例的基本要素包括测试用例编号、测试标题、重要性级别、测试输入、操作步骤和预期结果。
黑盒测试方法
- 等价划分(Equivalence Partitioning)
- 边界值分析(Boundary value analysis)
- 因果图(决策表)(Cause-Effect Graphs[Decision table])
- 随机测试(Random Testing)
- 错误猜测(Error Guessing)
- 场景测试(Scenario Testing)
等价划分(Equivalence Partitioning)
- 就是将所有可能的输入数据,即程序的输入域,划分为若干部分(子集),然后从每个子集中选取几个有代表性的数据作为测试用例,该方法是一种重要且常用的黑盒测试用例设计方法,有两种类型的等价类(qeuivalence class):有效等价类(effective equivalence class)和无效等价类(invalid equivalence class)
- 有效等价类(effective equivalence class)它是指对程序的规范来说合理且有意义的输入数据的集合。
有效等价类可以用来检查程序是否实现了规范中规定的功能和性能。 - 无效等价类(invalid equivalence class):与有效等价类的定义相反。无效等价类是指对于程序规范来说不合理或无意义的输入数据集。对于具体问题,至少应该有一个无效的等价类,也可以有多个。
- 等价分类标准:完成测试并避免冗余,划分等价类重要的是把集合分成一组不相交的子集,子集就是整个集合
边界值分析(Boundary value analysis)
- 就是对等价划分的补充,比如我只允许输入为
0-255,那我就检测-1,0,1,254,255,256
因果图(决策表)(Cause-Effect Graphs[Decision table])
- 前面介绍的等价划分和边界值分析都侧重于考虑输入条件,但没有考虑输入条件之间的联系和组合。
- 考虑输入条件的组合可能会导致一些新的情况,但检查输入条件的组合并不是一件容易的事,即使所有输入条件都被划分为等价的类,它们之间的组合仍然相当多。因此,有必要考虑以适合描述多个条件的组合并相应地生成多个动作的形式来设计测试用例。这需要使用因果图(又称石川馨图/鱼骨图)
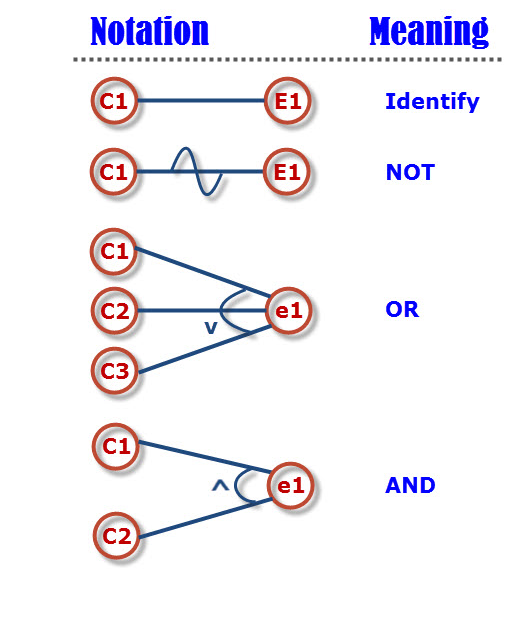
- 还有一些约束符号
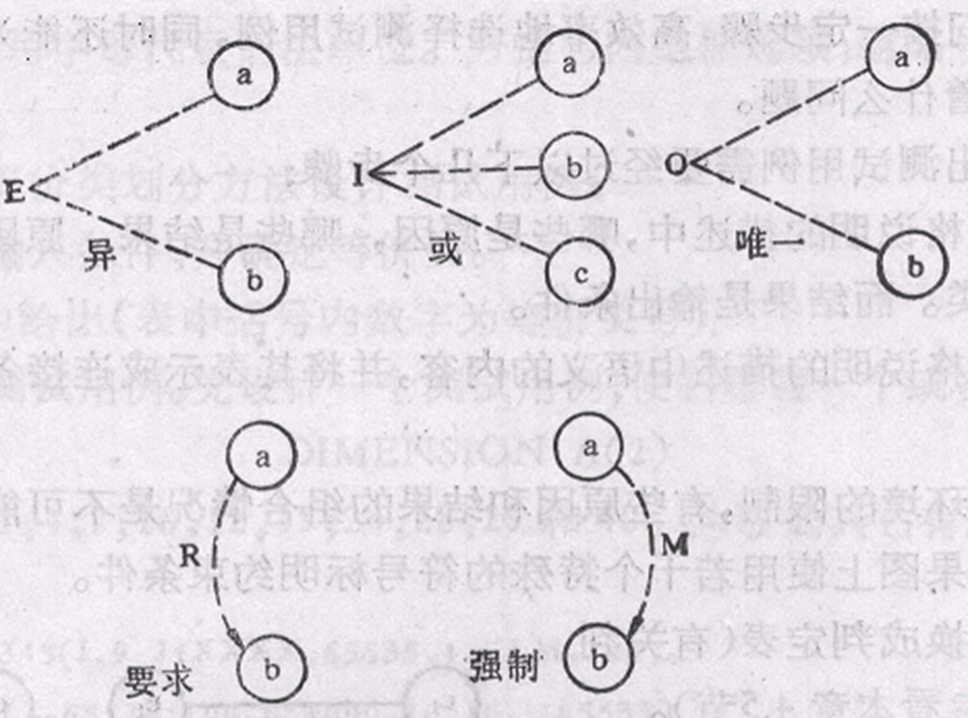
- 因果图方法的最终结果是判定表(Decision table),因此因果图的使用顺序是:
- 通过分析规格说明,为每个原因(输入)和结果(输出)分配标识符
- 根据关系画出因果图
- 标明限制条件
- 把图转换为判定表
- 把判定表的每一列拿出来作为依据
- 判定表的建立步骤:
- 确定规则的个数.假如有
- 列出所有的条件桩和动作桩。
- 填入条件项。
- 填入动作项。等到初始判定表。
- 简化.合并相似规则(相同动作)。
- 确定规则的个数.假如有
示例
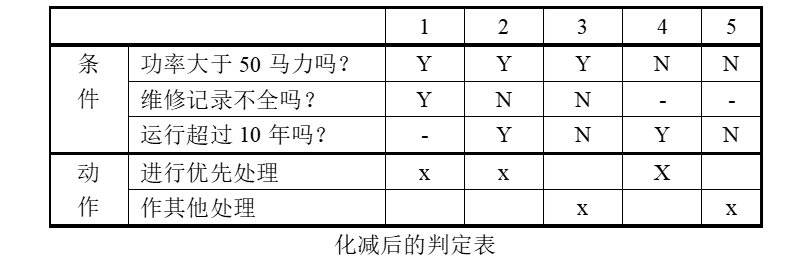
- 问题要求:”……对功率大于 50 马力的机器、维修记录不全或已运行 10 年以上的机器,应给予优先的维修处理……” 。这里假定,“维修记录不全”和“优先维修处理”均已在别处有更严格的定义 。请建立判定表
- 确定规则的个数:这里有 3 个条件,每个条件有两个取值,故应有
- 列出所有的条件茬和动作茬:

- 填入条件项。可从最后 1 行条件项开始,逐行向上填满。
- 填入动作桩和动作顶。这样便得到形如图的初始判定表。
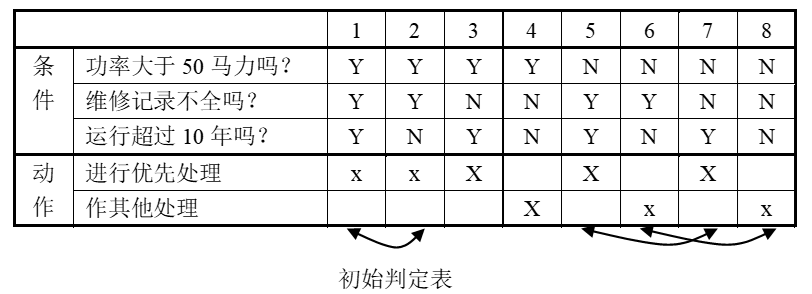
- 化简,合并相似规则
随机测试(Random Testing)
- 测试数据是使用随机数生成器生成的。
- 该分布可以是均匀的,或者被选择为在统计意义上模拟程序在实际使用中将接收的输入类型。
- 如果规范写得清楚且详尽,那么应该可以找到可能的输入值的集合。
- 目标是根据每个输入参数的分布实现其可能值的“合理”覆盖。 这可以通过启发式方式确定(例如,使用 10 个随机值),或者基于根据覆盖范围内所需的置信度确定的统计样本大小。
- 每个测试用例都由一组(随机)输入值表示,每个输入值对应一个参数。
- 然后,测量的测试故障率可以指示使用中的预期故障率
错误估测(Error Guessing)
- 这是一种基于直觉和经验的临时方法(ad-hoc approach)。
- 通过选择性地使用一些测试数据,例如
null ptr、空字符串,0 值,NaN 等 - 目标是覆盖尽可能多的值,根据测试人员的经验,这些值可能会暴露代码中的错误
场景测试(Scenario Testing)
- 场景测试是一种软件测试技术,它使用场景(即推测性故事)来帮助测试人员解决复杂的问题或测试系统。
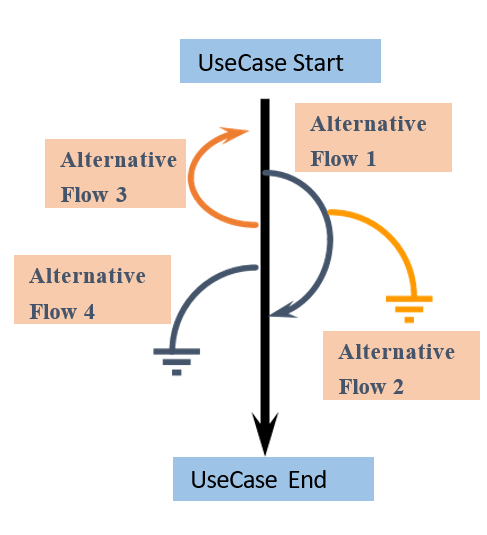
- 基本流程(basic flow):最简单的贯穿用例的路径,即没有任何错误,程序直接从头到尾的流程。大多数用户最常用的操作流程,反映了软件的主要功能和流程。 一项业务只有一个基础流,并且基础流只有一个起点和一个终点。
- 替代流程(alternative flow):从基础流程开始,在特定条件下执行,然后重新加入基础流程(例如替代流程 1 和 3),或者源自另一个替代流(例如替代流 2),用例也可以终止而不添加到基础中流(例如替代流 2 和 4),反映各种异常和错误情况。
场景测试的步骤
- 根据规范,描述被测软件的基本流程和替代流程。
- 构建不同的场景,满足测试完整性、无冗余的要求。
- 针对每个场景设计相应的测试用例。
- 重新检查所有生成的测试用例,删除多余的测试用例。 确定测试用例后,确定每个测试用例的测试数据值。
顺序值测试(Sequence and value testing)
值的序列对于软件保存状态很重要。
对特定输入值的响应可能会根据状态而变化,并且状态取决于先前的值序列。
分析序列的常规方法是使用状态图来识别软件可以处于的状态,以及每个状态下对每个输入(“事件”)的响应(“操作”)。
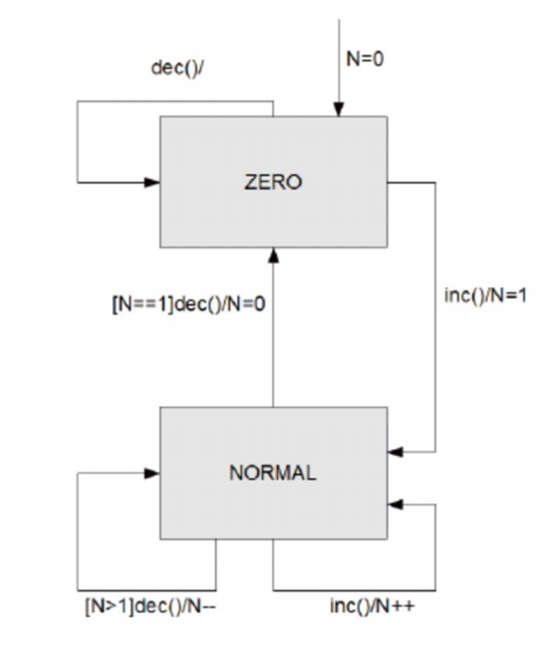
状态:系统实体生命周期中的抽象情况(例如,对象的内容)
过渡:允许的二态序列。 由事件引起
活动:输入或时间间隔
动作:事件之后的输出
守卫:与事件关联的谓词表达式,声明转换为触发态的布尔限制
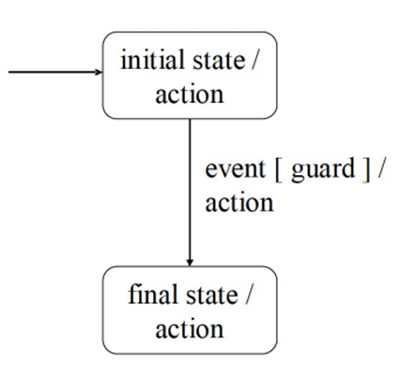
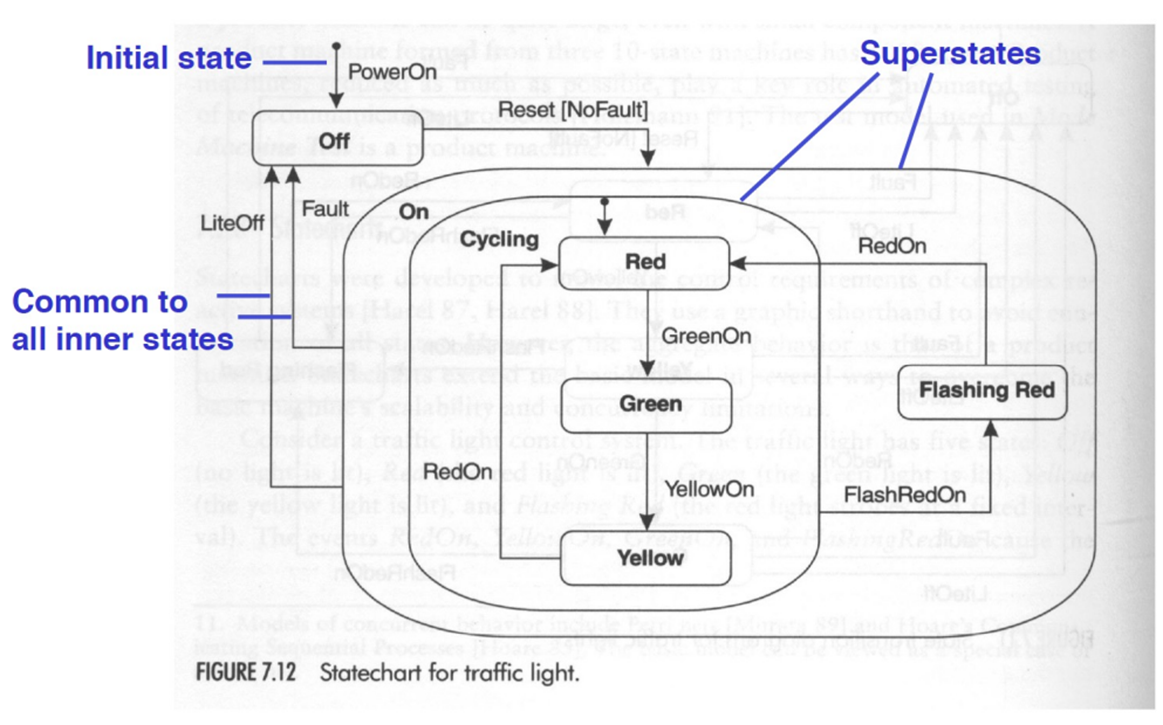
- 测试用例 = 输入事件序列
- 全部事件覆盖(All events coverage):测试套件(test suite)中包含状态机的每个事件,即每个事件至少是某个测试用例的一部分。
- 全部状态覆盖(All states coverage):在测试过程中,通过测试套件中的某个测试用例至少激活一次状态机中的每个状态。
- 全部转换覆盖(All transitions coverage):每个转换至少被一次测试用例激活。
- 全部路径覆盖(All path coverage):从入口到退出状态的所有可能路径都被测试用例覆盖。由于图中没有退出状态,因此需要识别从入口到每个状态的所有路径。
- 全部循环覆盖(All circuits coverage):在图中,从同一个状态开始和结束的所有路径都被测试用例覆盖。
白盒测试
- 白盒测试,也称为
结构测试(structual testing)或逻辑驱动测试(logic driven testing),是一种从程序的控制结构(control structure)中导出测试用例的测试用例设计方法。 - 白盒测试使用
被测单元(unit under test)内部如何工作的信息,允许测试人员根据程序的内部逻辑结构(internal logical structure)和相关信息来设计和选择测试用例来测试程序。
覆盖率标准(Coverage Standard)
- 我们当然希望白盒测试覆盖尽可能多的分支,然而,由于循环的存在,遍历程序所有可能的路径是不现实的,例如一个
if-else循环二十次,就有- 语句覆盖(Statement Coverage):意味着选择足够的测试用例,使得程序中的每条语句至少可以执行一次。
- 判定覆盖/分支覆盖(Decision Coverage/Branch Coverage):执行足够的测试用例,使得程序中的每个分支至少通过一次
- 条件覆盖(Condition Coverage):执行足够的测试用例,使得程序中判断的每个条件的每个可能值至少被执行一次;条件覆盖渗透到决策中的每个条件,但可能不满足决策覆盖的要求。
- 判断/条件覆盖(Decision/Condiction Coverage):设计足够多的测试用例,运行所测程序,使程序中每个判断的每个条件的所有可能取值至少执行一次,并且每个可能的判断结果也至少执行一次,换句话说,即是要求各个判断的所有可能的条件取值组合至少执行一次;
- 条件组合覆盖(Conditional combination coverage):执行足够的示例,以便每个决策中各种可能的条件组合至少出现一次。
- 基本路径覆盖(basic logic test):设计足够多的测试用例,运行所测程序,要覆盖程序中所有可能的路径。这是最强的覆盖准则。但在路径数目很大时,真正做到完全覆盖是很困难的,必须把覆盖路径数目压缩到一定限度。
- 前五种准则又被称为逻辑驱动测试(Logic-Driven Testing)方法
逻辑驱动测试(Logic-Driven Testing)
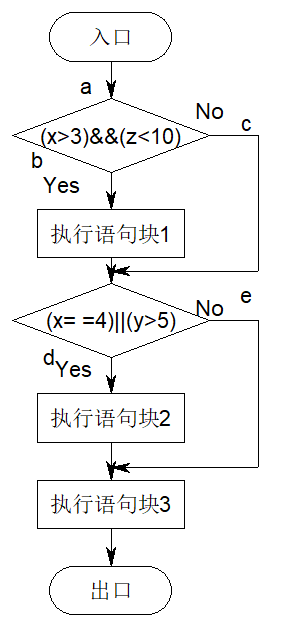
- 这里,我们记
语句覆盖(Statement Coverage)
- 语句覆盖无法判断逻辑问题,因为它并不能对逻辑分支做检查,例如,将示例图中的第一个
&&改为||,也并不能检查出来
判定覆盖/分支覆盖(Decision Coverage/Branch Coverage)
- 它能够使每一个分支都获得每一种可能的结果,对于对于例 1 中,我只要设计两个例子,通过路径
ace和abd或者通过路径acd和abe就可以达到判定覆盖,但是他也无法对判断条件进行检查,例如,我使用输入
x=4,y=5,z=5; //[a,b,d]
x=2,y=5,z=5; //[a,c,e]当第二个条件错误地写成y<5时,也无法检测出来
条件覆盖(Condition Coverage)
例 1 的程序有四个条件:
为了达到“条件覆盖”标准,需要执行足够的测试用例使得在 a 点有以下结果出现:
以及在 b 点有以下结果出现:
现在只需设计以下两个测试用例就可满足这一标准:
- 但是它无法保证所有分支都被执行到,例如
IF A AND B THEN S,我们设计用例为(A,!B),(!A,B),那么S永远无法被执行到
判断/条件覆盖(Decision/Condiction Coverage)
- 针对上述问题,引入了另一种覆盖标准“分支/条件覆盖”。其含义是执行足够多的测试用例,使得一个分支中的每个条件都可以获得各种可能的值,并且每个分支都可以获得各种可能的结果。
- 对于例 1,我们可以设计
| 条件取值 | 通过路径 | 覆盖分支 |
|---|---|---|
| abd | bd | |
| ace | ce |
- 然而,它无法判断条件的正确性,例如
条件组合覆盖(Conditional combination coverage)
- 针对上述问题,提出了另一个标准“条件组合覆盖”。其含义是执行足够多的示例,使得每个决策中各种可能的条件组合至少出现一次。
- 但是这种方法不能保证所有路径都被遍历到,因为它不要求分支的条件组合
补充策略
- 任何方法都不可能提供一组"完整的"测试用例,因此总是需要补充,一种参考的黑盒法补充策略是:
- 使用边界值分析。
- 用等价分类法补充一些测试用例。
- 再用错误推测法附加测试用例。
- 检查上述例子的逻辑覆盖程度,如果未能满足某些覆盖标准,则再增加足够的测试用例。
- 如果功能说明中含有输入条件的组合情况,则一开始就可先用因果图(判定表)法。
基本路径测试(Basic Path Testing)
- 在例 1 中,我们可以很简单地遍历所有可能的路径,然而在实际程序中这是不可能的(指数爆炸!),但是我们可以通过一些手段进行剪枝,也就是压缩覆盖的路径数,比如通过只运行一次循环体
- 下面介绍的方法就是在
程序控制图的基础上,通过分析控制构造的环行(圈,loop)复杂性,导出基本可执行路径集合,从而设计测试用例的方法,设计出的测试用例要保证在测试中程序的每一个可执行语句至少执行一次。 - 通常包括四个步骤:
- 程序的控制流图:描述程序控制流的一种图示方法
- 程序圈复杂度:McCabe 复杂性度量。从程序的环路复杂性可导出程序基本路径集合中的独立路径条数。
- 导出测试用例:根据圈复杂度和程序结构设计用例数据输入和预期结果。
- 准备测试用例:确保基本路径集中的每一条路径的执行
- 一个方法:
- 图形矩阵:是在基本路径测试中起辅助作用的软件工具,利用它可以实现自动地确定一个基本路径集。
控制流图
- 流图只有二种图形符号,图中的每一个圆称为流图的结点,代表一条或多条语句。流图中的箭头称为边或连接,代表控制流。
- 任何过程设计都要被翻译成控制流图。
- 在将程序流程图简化成控制流图时,应注意:
- 在选择或多分支结构中,分支的汇聚处应有一个汇聚结点。
- 边和结点圈定的区域叫做区域,当对区域计数时,图形外的区域也应记为一个区域。
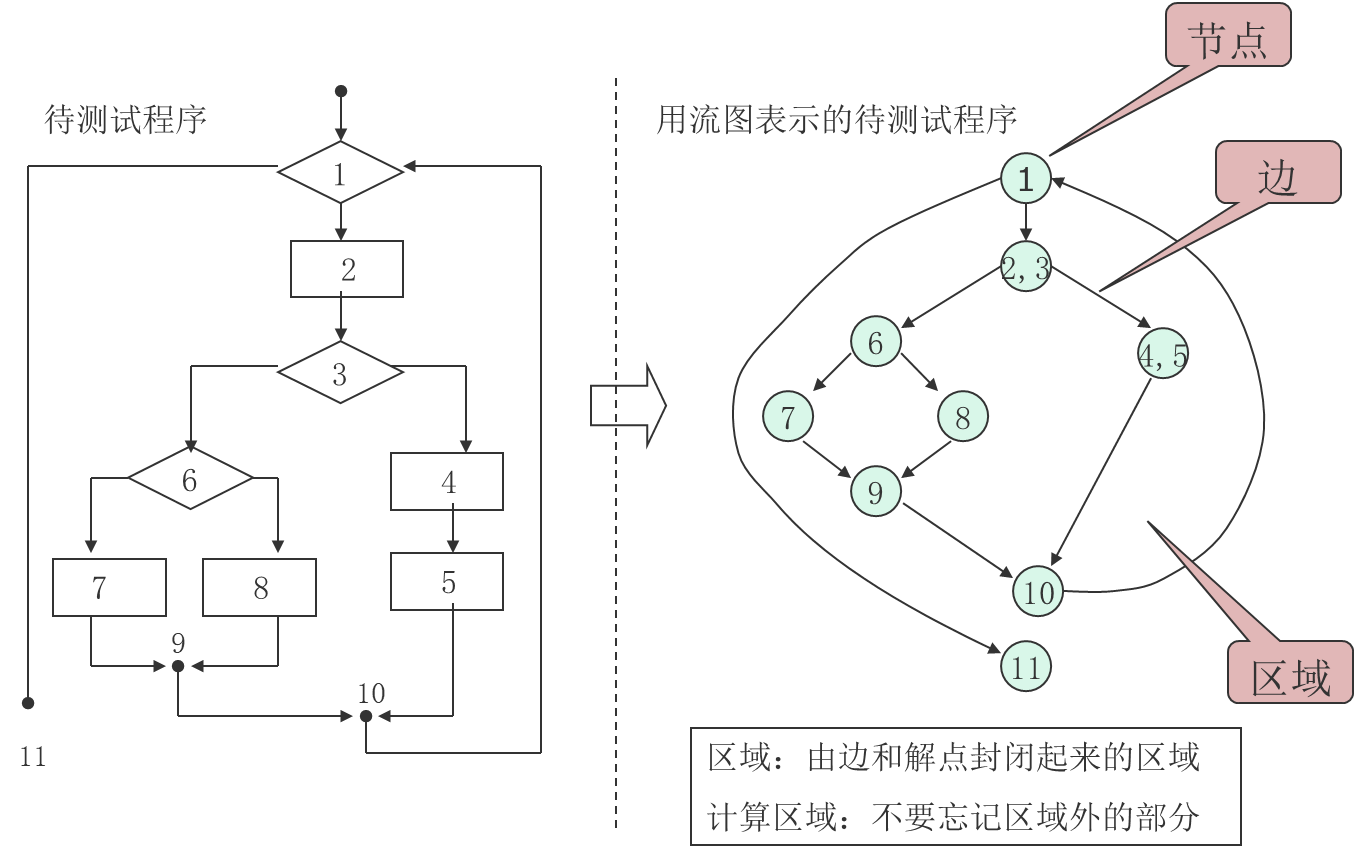
- 如果判断中的条件表达式是由一个或多个逻辑运算符 (OR, AND, NAND, NOR) 连接的复合条件表达式,则需要改为一系列只有单条件的嵌套的判断。
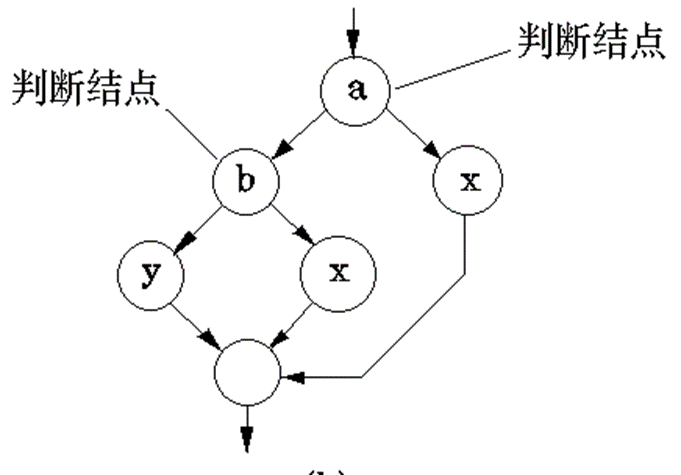
- 例如下列代码和对于图
if (a||b){
x
}else{
y
}
独立路径(Independent Path)
至少沿着一条新的边移动的路径
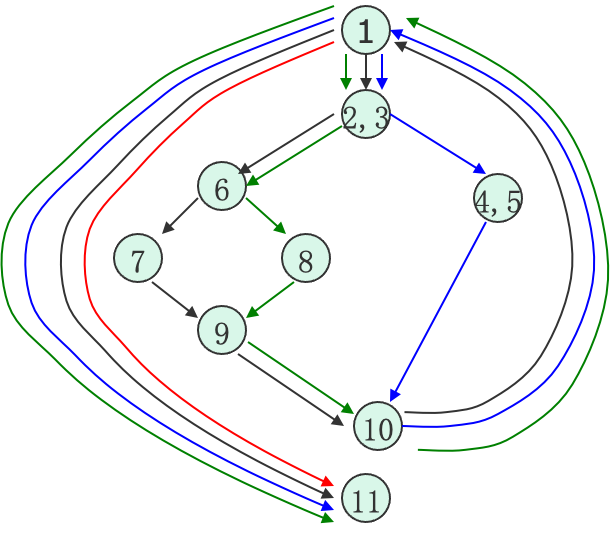
按照以下路径遍历,就是至少一次地执行了程序中的所有语句:
- 路径 1:1-11
- 路径 2:1-2-3-4-5-10-1-11
- 路径 3:1-2-3-6-8-9-10-1-11
- 路径 4:1-2-3-6-7-9-10-1-1
步骤
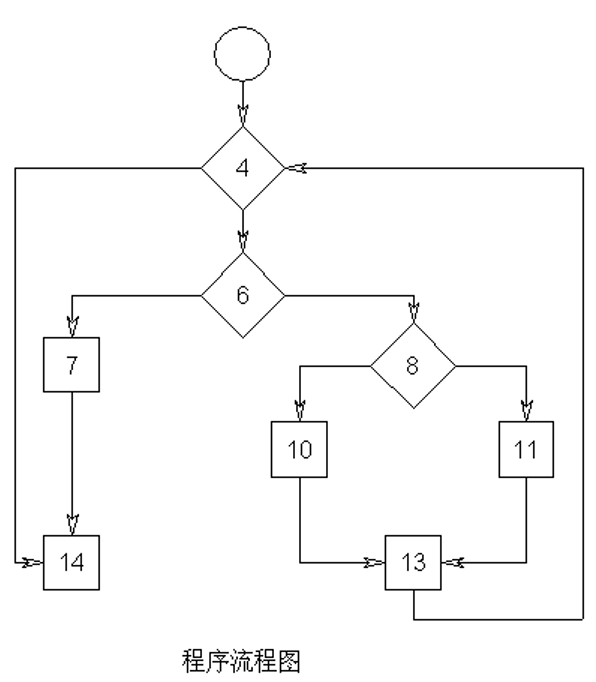
例 4:有下面的 C 函数,用基本路径测试法进行测试
void Sort(int iRecordNum,int iType)
{
int x=0;
int y=0;
while (iRecordNum-- > 0)
{
if(0= =iType)
{ x=y+2; break;}
else
if (1= =iType)
x=y+10;
else
x=y+20;
}
}- 第一步:画出控制流图:
- 流程图用来描述程序控制结构。
- 可将流程图映射到一个相应的流图(假设流程图的菱形决定框中不包含复合条件)。
- 在流图中,每一个圆,称为流图的结点,代表一个或多个语句。
- 一个处理方框序列和一个菱形决测框可被映射为一个结点,流图中的箭头,称为边或连接,代表控制流,类似于流程图中的箭头。
- 一条边必须终止于一个结点,即使该结点并不代表任何语句(例如:if-else-then 结构)。
- 由边和结点限定的范围称为区域。
- 计算区域时应包括图外部的范围。
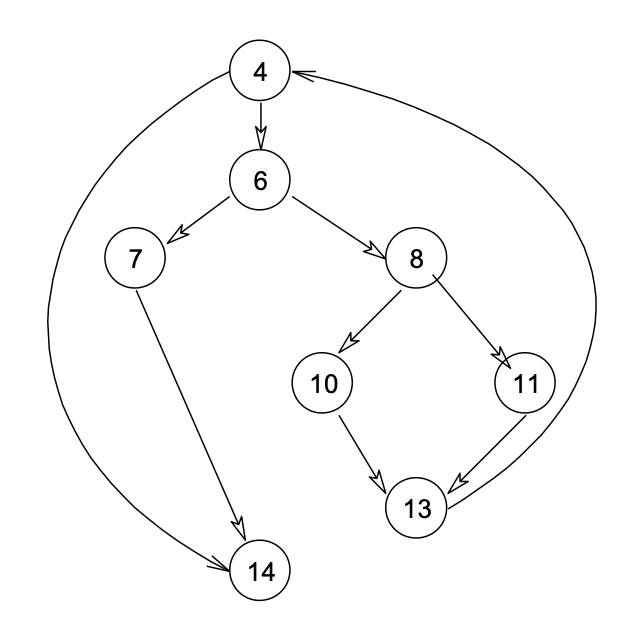
- 第二步:计算圈复杂度(Cyclomatic complexity/循环复杂度)
- 圈复杂度是一种为程序逻辑复杂性提供定量测度的软件度量,将该度量用于计算程序的基本的独立路径数目。
- 独立路径必须包含一条在定义之前不曾用到的边。
- 有以下三种方法计算圈复杂度:
- 流图中区域的数量对应于环型的复杂性;
- 给定流图
- 给定流图
- 对应上面图中的圈复杂度,计算如下:
- 流图中有四个区域;
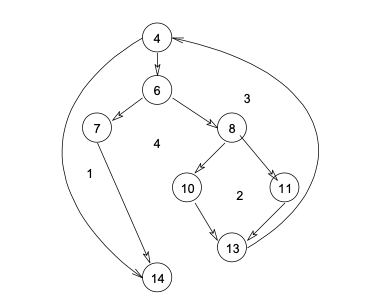
- 第三步:导出测试用例
- 根据上面的计算方法,可得出四个独立的路径。(一条独立路径是指,和其他的独立路径相比,至少引入一个新处理语句或一个新判断的程序通路。V(G)值正好等于该程序的独立路径的条数。)
- 路径 1:4-14
- 路径 2:4-6-7-14
- 路径 3:4-6-8-10-13-4-14
- 路径 4:4-6-8-11-13-4-14
- 根据上面的独立路径,去设计输入数据,使程序分别执行到上面四条路径。
- 根据上面的计算方法,可得出四个独立的路径。(一条独立路径是指,和其他的独立路径相比,至少引入一个新处理语句或一个新判断的程序通路。V(G)值正好等于该程序的独立路径的条数。)
- 第四步:准备测试用例
- 为了确保基本路径集中的每一条路径的执行,根据判断结点给出的条件,选择适当的数据以保证某一条路径可以被测试到
图形矩阵(Graphic Matrix)
- 导出控制流图和决定基本测试路径的过程均需要机械化,为了开发辅助基本路径测试的软件工具,称为
图形矩阵(Graphic Matrix)的数据结构很有用。 - 利用图形矩阵可以实现自动地确定一个基本路径集。
- 一个图形矩阵是一个方阵,其行/列数控制流图中的结点数,每行和每列依次对应到一个被标识的结点,矩阵元素对应到结点间的连接(即边)。
- 在图中,控制流图的每一个结点都用数字加以标识,每一条边都用字母加以标识。
- 如果在控制流图中第 i 个结点到第 j 个结点有一个名为 x 的边相连接,则在对应的图形矩阵中第 i 行/第 j 列有一个非空的元素 x。
- 对每个矩阵项加入连接权值,图矩阵就可以用于在测试中评估程序的控制结构,连接权值为控制流提供了另外的信息。最简单情况下,连接权值是 1(存在连接)或 0(不存在连接),但是,连接权值可以赋予更有趣的属性:
- 执行连接(边)的概率。
- 穿越连接的处理时间。
- 穿越连接时所需的内存。
- 穿越连接时所需的资源。
- 对例 4 画出图形矩阵如下
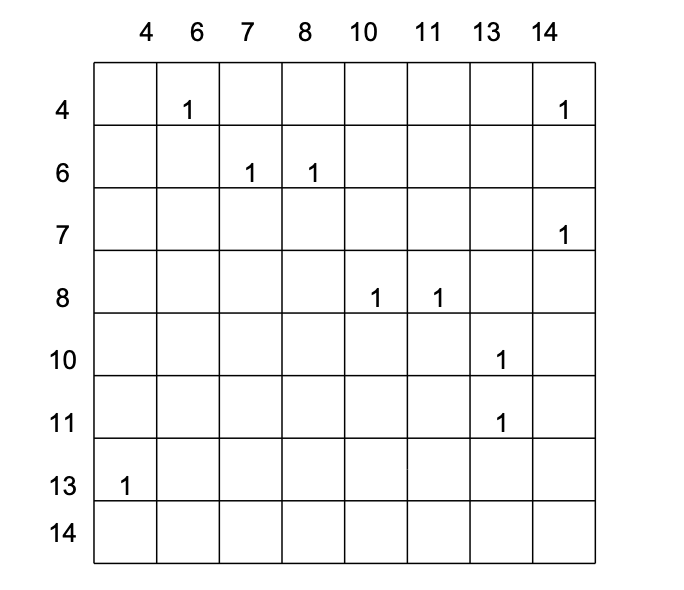
- 连接权为“1”表示存在一个连接,在图中如果一行有两个或更多的元素“1”,则这行所代表的结点一定是一个判定结点,通过连接矩阵中有两个以上(包括两个)元素为“1”的个数,就可以得到确定该图圈复杂度的另一种算法。
数据流测试(Data-Flow Testing)
- 数据流测试使用控制流程图来探索数据可能发生的不合理情况(即异常)。
- 对数据流异常的考虑导致了测试路径选择策略,该策略填补了完整路径测试和分支或语句测试(语句测试)之间的空白。
- 数据流测试是一系列测试策略的名称,这些测试策略基于选择程序控制流的路径,以探索与数据对象状态相关的事件序列。(揭示相关的数据对象状态的事件顺序)。例如,选择足够的路径以确保:
- 每个数据对象在使用之前都已初始化。
- 所有定义的对象都至少使用过一次。
数据对象分类(Data Object Categories)
- Defined, Created, Initialized
- Killed, Undefined, Released
- Used:
- Used in a calculation(计算使用)
- Used in a predicate(谓词使用)
例如:
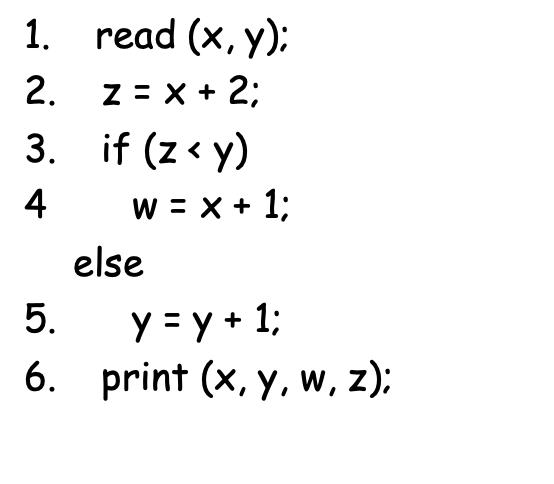
| def | C-use | P-use |
|---|---|---|
| x,y | ||
| z | x | |
| z,y | ||
| w | x | |
| y | y | |
| x,y,w,z |
数据流模型(Data-Flow Modeling)
数据流建模基于控制流程图。
每个链接都附有注释:
- 符号(例如 d、k、u、c、p)
- 符号序列(例如 dd、du、ddd)
- 表示该链接上与感兴趣的变量相关的数据操作序列。
简单路径段(Simple Path Segments)是最多一个节点被访问两次的路径段。例如,(7,4,5,6,7) 很简单。因此,简单路径可能是无环路,也可能不是无环路。
无循环路径段(Loop-free Path Segment)是每个节点最多被访问一次的路径段。例如,(4,5,6,7,8,10) 是无循环的。路径 (10,11,4,5,6,7,8,10,11,12) 不是无循环的,因为节点 10 和 11 被访问了两次。
定义-使用路径(define-use/du Path):关于变量 v 的定义使用路径(记作 du-path),存在定义节点
定义-使用关联(def-use Associations)是一个三元组
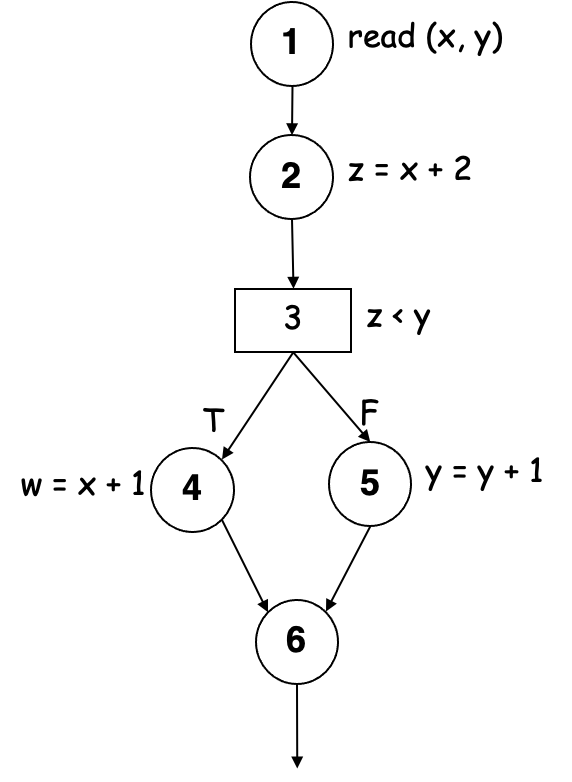
- 定义-清除路径(Define-Clear Path):一条路径
静态测试(Static Testing)
- 静态测试,通过检查和评审软件而不是运行软件来测试软件的方法。
- 静态测试对象,待测试的软件相关产品,各种文档、源代码等
- 识别错误的成本,需求阶段识别重要 Bug 平均需要 2-3 小时,在设计阶段识别一个重要的 bug 平均需要 3-4 个小时,代码评审阶段识别重要 bug 3-5 小时,动态测试平均需要 15-25 小时才能识别重要错误
- 静态分析主要由软件工具自动执行,广义上讲,它还包括设计阶段的软件需求分析和技术审查,一群程序员和测试人员组成一个小组,集体阅读和讨论一个程序,或者用“大脑”来执行和检查程序的过程
代码审查(Code Review)
- 由一组程序和错误检查技术组成
- 以代码审查组方式进行
- 四个步骤
- 准备
- 程序阅读
- 审查会
- 跟踪及报告
代码走查(Code Walkthrough)
- 它也是由一组程序和错误检查技术组成,只是程序和错误检查技术不完全相同
- 与代码审查不同,不是读程序和使用代码审查单,而是由被指定的作为测试员的小组成员提供若干测试用例(程序的输入数据和期望的输出结果),让参加会的成员当计算机,在会议上对每个测试用例用头脑来执行程序,也就是用测试用例沿程序逻辑走一遍,并由测试人员讲述程序执行过程,在纸上或黑板上监视程序状态(变量的值)
- 代码走查中,测试用例并不是关键,也并不是仅想验证这几个测试用例运行是否正确,人脑毕竟比计算机慢太多
- 这里测试用例是作为怀疑程序逻辑与计算错误的启发点,在随测试实例遍历程序逻辑时,在怀疑程序的过程中发现错误,这比几个测试用例本身直接发现的错误要多得多
代码走查的缺点
- 代码走查使用测试用例启发检测错误,人们注意力会相对集中在随测试用例遍历的程序逻辑路径上,不如代码审查检查的范围广,错误覆盖面全
静态测试的分类
- 需求定义的静态测试
- 设计文档的静态测试
- 源代码的静态测试
需求定义的静态测试
- 高级审查:测试需求定义的第一步是站在一个高度上进行审查,找出根本性的问题、疏忽或遗漏之处。例如符不符合政策规定,法务要求,功能需求是否都包含在了规格说明书中
- 低层测试:高级审查之后可以很好地了解产品以及影响其设计的外部因素,然后就可以在更低的层次测试需求定义了。一些词语往往会带来缺陷,例如
如果...那么...,没有否则,如果没有发生时就会带来缺陷。除此之外还包括这些对照条例:- 完备性,例如是否对所有功能与时间有关的方面都作了考虑?
- 一致性,例如需求是否与其软硬件操作环境相容?
- 正确性,例如对设计和实现的限制是否都有论证?
- 可行性:例如需求定义是否使软件的设计、实现、操作和维护都可行?
- 易修改性
- 健壮性
- 易追溯性
- 易理解性
- 易测试性和可验证性
- 兼容性
设计文档的静态测试
- 对设计文档的静态测试着重于:
- 分析设计是否与需求定义一致
- 所采用的数值方法和算法是否适用于待解问题
- 程序的设计中对程序的划分是否与待解问题相适应
- 需求是否都被满足了
- 同样的,对照条例包括:
- 完备性:是否有充分的数据(如逻辑结构图、算法、存储分配图等)来保证设计的完整性?
- 一致性:在设计文档中,是否始终使用标准的术语和定义?文档的风格和详细程度是否前后始终一致?
- 正确性:设计文档是否满足有关标准的要求?
- 可行性:设计能否在所规定的限制条件下和开发代价下实现?
- 易修改性:设计是否做到了高内聚低耦合
- 模块性:是否采用了模块化的机制,使得程序由若干个子程序组成
- 可预测性:设计是否包含了子程序来提供在已经标识出的出错情况下所需的反应?
- 健壮性:设计是否覆盖了需求定义中所要求的容错和故障弱化的需求?
- 结构化:设计是否使用了层次式的逻辑控制结构?
- 易追溯性:设计文档中是否包含设计与需求定义中的需求、设计限制等内容的对应关系?
- 易理解性:设计是否避免了不必要的成分和表达形式?
- 可验证性/易测试性
源代码的静态测试
- 对源代码的静态测试着重于分析实现是否正确、完备
- 对照条例包括:
- 完备性:代码是否完全、准确地实现了设计规约中所规定的内容?
- 一致性:是否自始至终使用了相同的格式、调用约定、结构等等?
- 正确性:变量的定义和使用都正确吗?
- 易修改性:代码中对常数的使用是否都通过符号来进行,使其便于修改?
- 可预测性:是否避免了依赖于程序设计语言中的缺省值的代码?
- 健壮性:代码是否防止可以发现的运行时刻的错误?如下标变量越界,除数为零,变量值越界,栈溢出等等
- 结构性:程序的每一个功能是否都可以作为一块代码而识别出?
- 易追溯性:是否有修改历史记录,它记录对代码的所有修改历史和修改原因?
- 易理解性:注释是否使用简洁明了的语言对每一个子程序都作了充分的描述?
- 可验证性:实现是否避免了使用测试难度大的技术和方法?