No Memory Abstraction
- 所有程序必须硬编码硬件物理地址
内存中不可能同时运行两个应用(也可以用方法实现同时存放 IBM360)
静态重定位(Static reloacation)
- 在进程加载到内存中的时候就映射到一个指定的物理地址上
- 优点是不需要硬件支持
- 缺点是会减慢加载的速度,而且加载后不再能在内存中移动位置,除非再进行一次重定位,而且加载器需要用某种方式显式地声明哪个是地址,哪个是常量
Address Space
简介
- 多程序系统中十分重要的是对内存的保护和重定位,为了解决这两个问题提出了 Address Space
- Address Space 指的是一组能被一个进程所使用的内存地址
动态重定位(Dynamic Relocation)
- 把每个进程地址映射为一个物理地址
- 物理地址空间的范围时
- 需要 CPU 硬件支持——需要基址寄存器(Base register),和大小寄存器(Limit register)
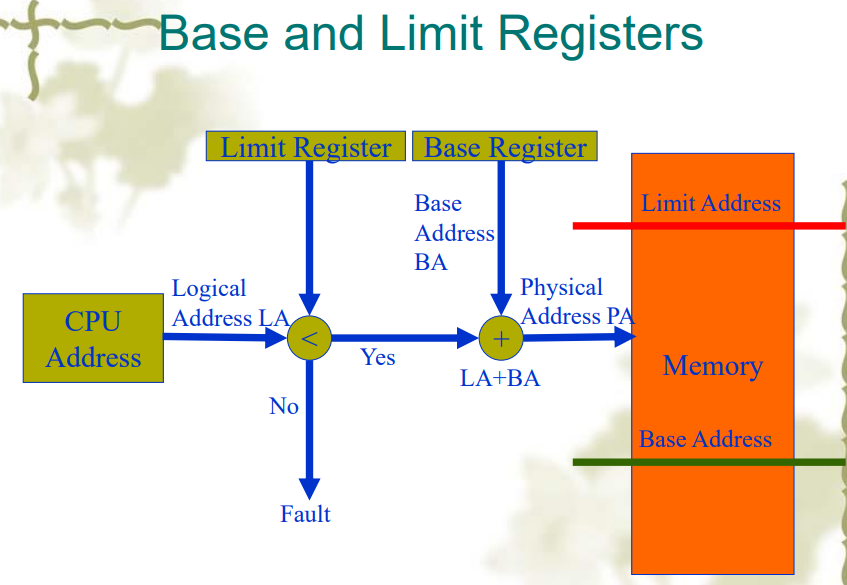

优点
- 操作系统可以在执行时简单地移动进程
- 操作系统可以动态地改变进程的大小(通过改变 limit register 或者移动位置)
- 简单,硬件速度块
缺点
- 降低运行速度,每次访问内存都要进行一次映射
- 不能在进程间共享内存
- 进程受限于物理内存大小(虚存就不受物理内存大小限制)
- 使得内存管理复杂化
Swap
- 把整个进程放进内存中执行一段时间后把它放回硬盘中,而虚存则是允许程序在只有部分存在于主存中时运行
- Swapping 允许多个进程共享内存的一部分
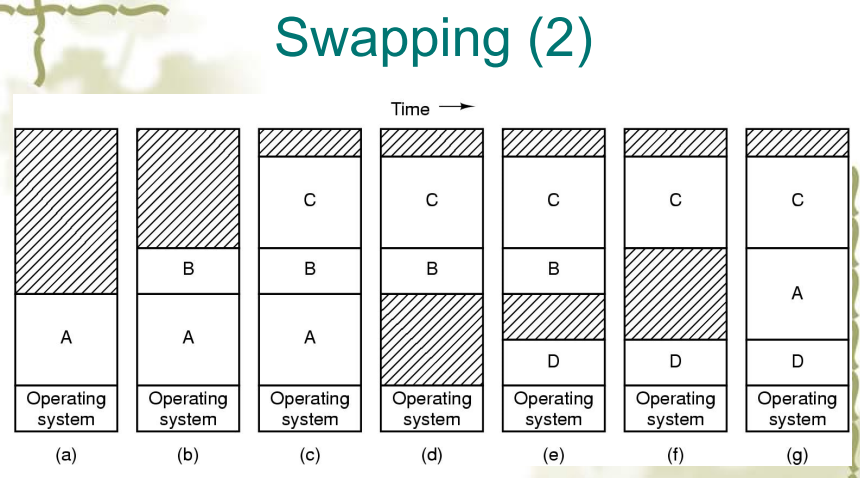
- 灰色部分都是在不断的换进换出中未被使用的内存,因此 swapping 方法会带来大量的 holes(外部碎片)
- 如果一个进程在运行过程中发生了增长,那么就需要先换出,再换入一个更大的 partion 中,这个过程会带来大量的开销。下图所示是一种方法,预留一片区域来扩展
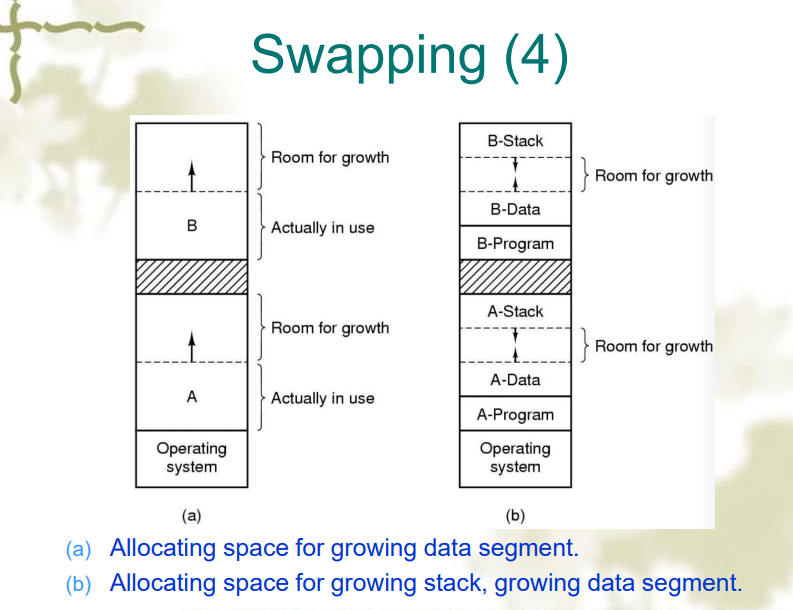
Compaction(压缩)
- 假设所有程序都是可重定位的,那么在碎片过多的时候就会进行压缩,在压缩的过程中进程必须被暂停
-pDbehKT6.png)
Memory Management
- 通过位图或者链表来追踪内存的使用情况
- hole 表示一段连续的空闲内存
位图(Bitmap)
- 一个内存分配单元对应位图中的一个 bit,0 表示空闲,1 表示已分配
- 缺点是每当一个新进程到达内存,都要在位图中查找一段连续的 0 来分配给新进程,这个操作是耗时的,而且这一系列连续的 0 也有可能是跨字的。
链表
- 每个链表项表示一个 hole(连续的空闲段)或者一个进程(已分配的端),包括这个段的大小和指向下个 entry 的指针。
- 可以单独维护一个空闲链表来节约查找时间
- 有按大小和按地址排序这两种方式,按地址排序的优点是当一个进程终止或被换出时,可以线性地向前更新链表,
分配策略
- First Fit:每次遍历都从链表头开始,遇到一个可用的就分配,但是会产生一些新的 holes(average)
- Next Fit:每次遍历都从上次分配的位置开始遍历,遇到一个可用的就分配,但是比 First Fit 的表现还稍差一点。
- Best FIt:分配时分配冗余量最少的内存空间,但是可能会带来一些无法使用的外部碎片
- Worst Fit:分配时直接分配最大的空间,但是会导致大空间可能分配给了小程序,导致大程序运行不了。
- Quick Fit:维护一个索引表,把一些大小范围内的空间用一个索引串起来,但是因为这些内存空间往往不连续,所以合并的复杂度高
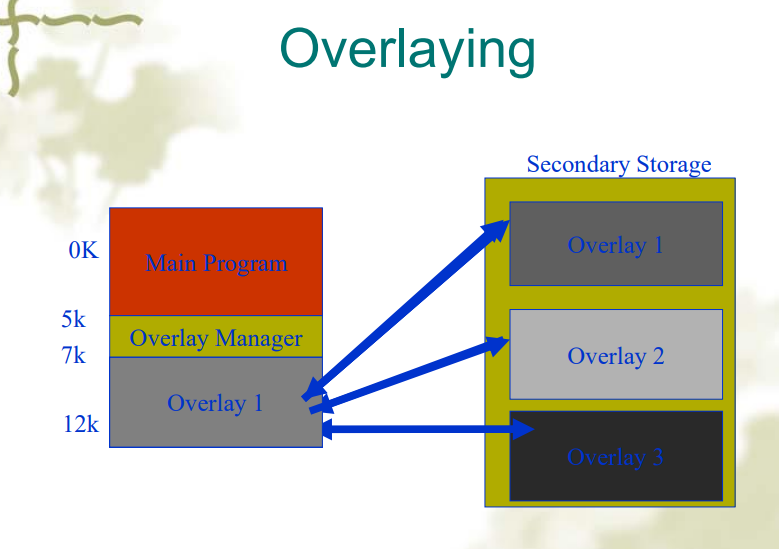
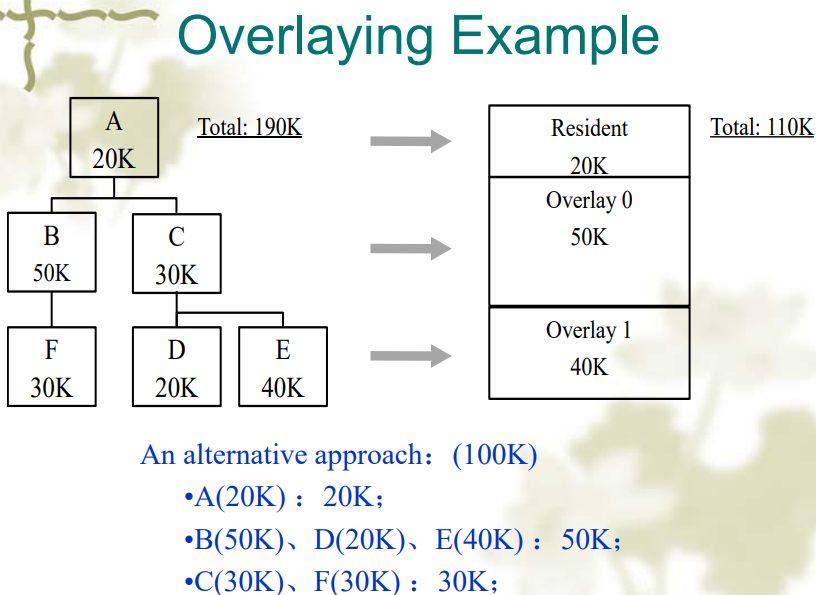
覆盖段(Overlaying)
- 程序的内存中有一部分被分配为覆盖段,当程序执行时,将外存中的其他覆盖段按需覆盖到内存的覆盖段中
- 覆盖段的切换是由操作系统完成的,但是覆盖段的划分要由用户划分。
虚拟存储(Virtual Memory)
局部性原理
- 时间局部性:数据被访问后大概率在时间局部范围内还会被访问
- 空间局部性:数据被访问后其前后的的数据也会大概率被访问
虚存的实现
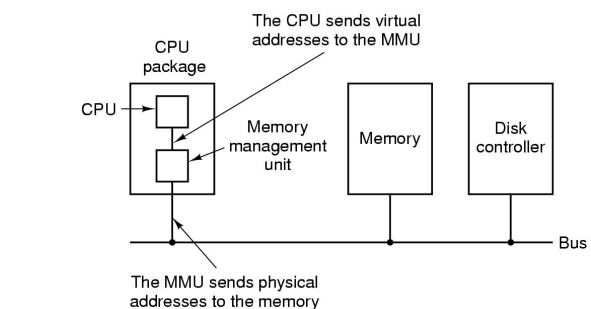
分页(Paging)
- 通过 MMU(Memory Management Unit)来把一个虚拟地址映射到物理地址
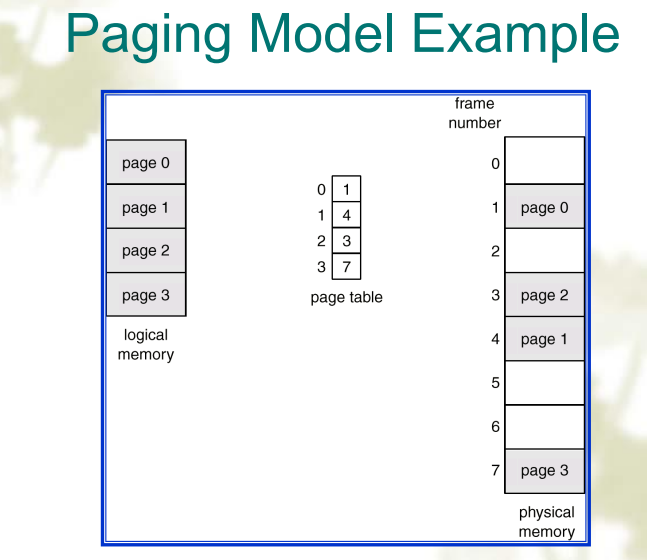
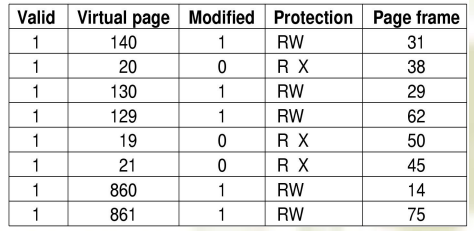
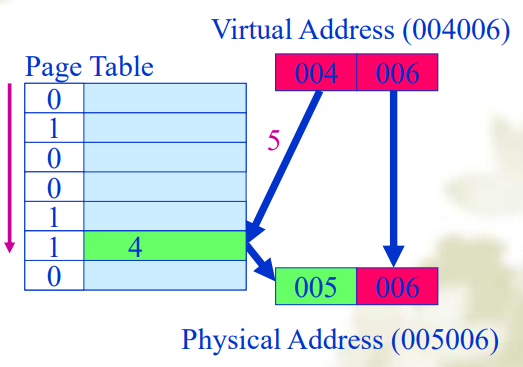
页表(Page Table)
- 由虚页号(高位)和页内偏移量(低位)决定
- 用来从虚页映射到页帧(主存中)
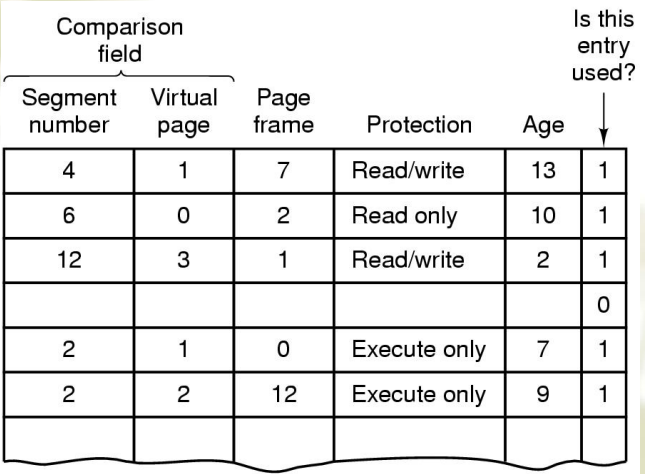
- 一个页表项还有其他字段:
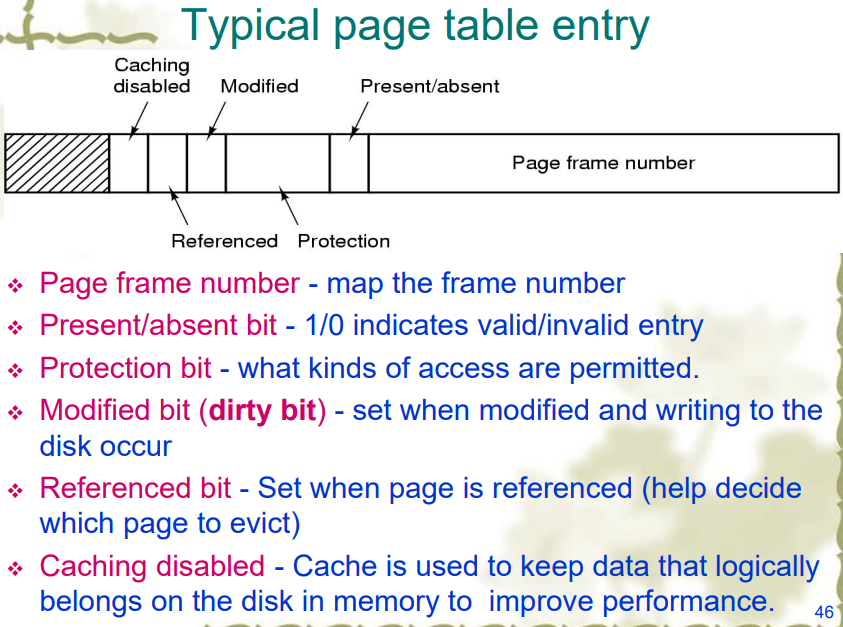
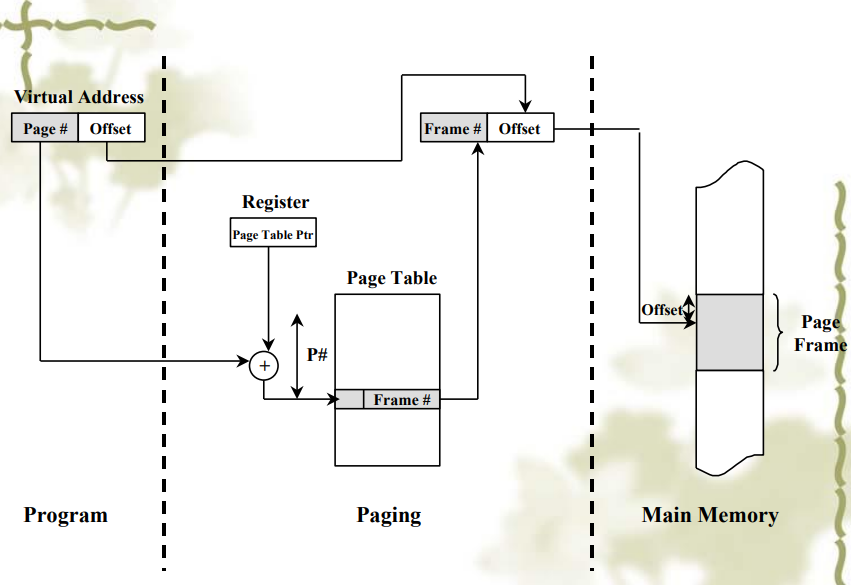
问题
- 需要尽可能快地进行映射,因为每次内存访问都需要用 page table 进行映射
- page table 可能很大
TLB(Translation Look-aside Buffers)
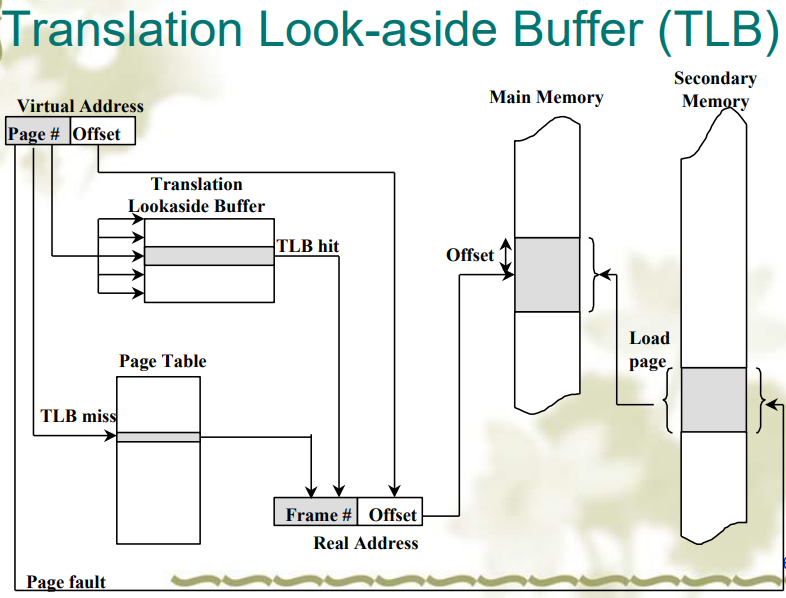
- 又被称为相联存储器(associated memory),是基于内容而不是索引进行访问,而且由于硬件特性,可以并行比较
硬件控制 TLB

软件控制 TLB

多级页表
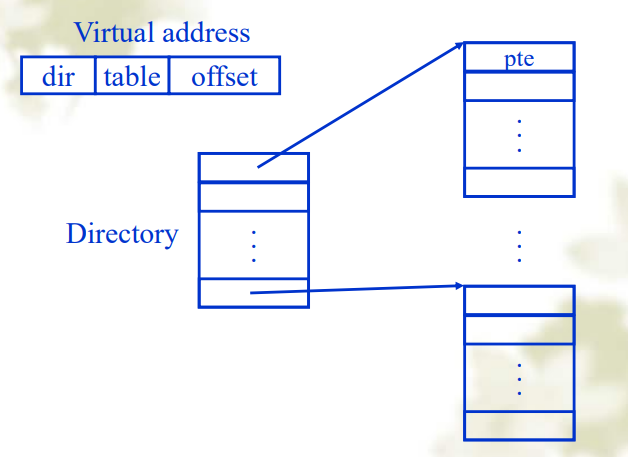
- 可以减少表的大小,而且内存可以只保存部分需要的页表,但是减慢了内存访问的速度。
倒排页表(Inverted Page Tables)
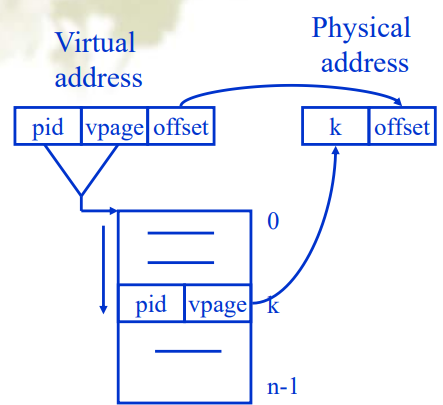
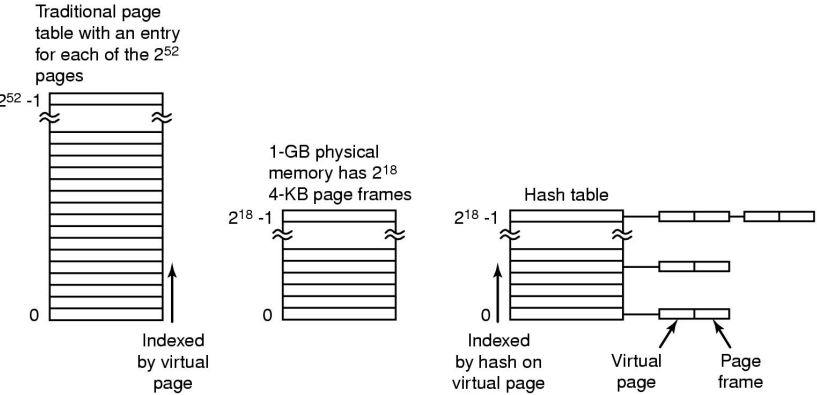
- 储存的是每个物理页框的信息,因为物理内存大小往往远小于虚拟内存,因此能节约空间,好处是可以用较小地页表获得一个较大地地址空间,缺点是难以查找,哈希表项的链表可能过长。
Page Replacement Algorithm
目录
- Fetch Strategies
- Replacement Algorihm
- Clean policy
- Paging in OS
Fetch Strategies
Demand Fetching
- 该算法只有在需要的时候才会把 page 换入主存中
steps
- 出现 page fault
- 检查虚存地址是否有效,如果是无效地址则 kill the job
- 如果有效,就检查内存中有没有这个页,如果有就跳到第七步
- 找到一个可用的页帧
- 把地址映射到磁盘的块上,然后把磁盘的块换入到页帧中,中止用户进程
- 当硬盘读完后,添加虚存到这个页帧的映射表项
- 需要的话,重启进程
Prepaging
- 该算法提前把 page 换入主存中
- 当出现 page fault 并把页换入主存时,把它邻近的页一起换入主存中
- 优点是可以提高 I/O 效率
- 缺点是这个算法是需要预测的,如果 fetch 的 page 几乎没有被使用,反而效率降低了
- 常用在程序刚开始时,一次载入大量 page
Replacement
steps
- 找到 page 在硬盘上的位置
- 找到空闲的 page frame
- 如果有一个空白页帧,就使用它
- 如果没有空白页帧就通过页面置换算法来选取一个页帧(victim frame)
- 如果需要的话,把这个选取的页写入硬盘,并更新表
- 从硬盘中读出所需的页,放到页帧中
- 重启用户进程。
Reference String
- 指的是访问页的序列,即为
- 例如:页大小为 100,依次访问内存地址为 233,150,1233,89,98,则 Reference String 为 2,1,12,0
算法
- The Optimal Algorihm(OPT or MIN):
- Random page replacement Algorithm
- FIFO(First-in First-Out) Algorithm
- Second CHance Algorithm
- Clock Algorithm
- NRU(Not Recently Used)Algorithm
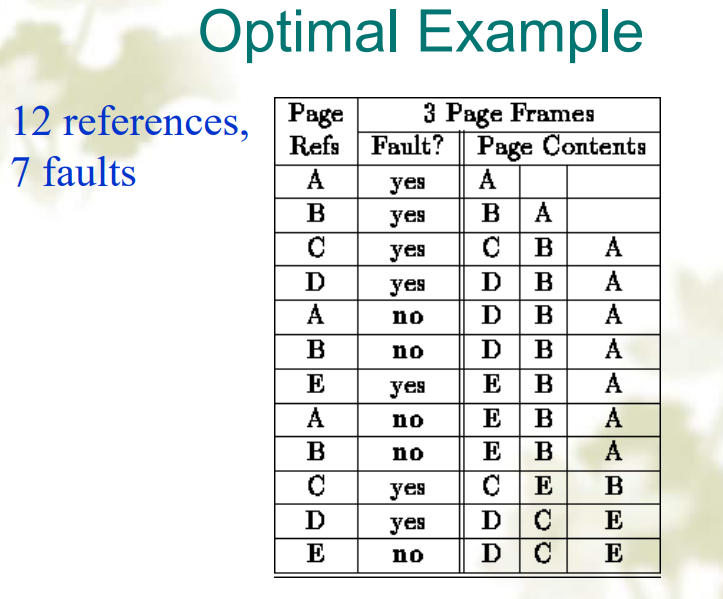
The Optimal Algorithm
- 把将来最少访问的 page 移出
- 能带来最少的 page faults
- 但是并不常用,因为需要未来预测,如果能预测未来,那就会使用 prepaging 而不是 demand fetching
描述
- 每个 page 用一个数字标识在它被使用前还需要经过的指令条数,这个数字越大说明将来使用越少,在需要被置换的时候选取数字最大的 page
例子
FIFO
- 维护一个 FIFO 链表,先进先出
- 链表头的 page 被换出
- 优点是易于实现,缺点是这种方法只考虑到了进入时间,没考虑到页在内存中的使用情况,容易导致反复 page fault
Belady's anomaly
- 一般情况下,page frame 越多,应该 page fault 越少,但是还有其他因素
- page fault 还与 reference string、page replacement 算法和内存中可用的 page frame 数量有关
Second Chance
- 在 FIFO 的基础上进行改进
- 在 page 上标记一个引用位 R,当 page fault 发生时
The Clock Page Replacment(Aging)
- 就是把 Second Chance 算法中的链表改成了环形链表
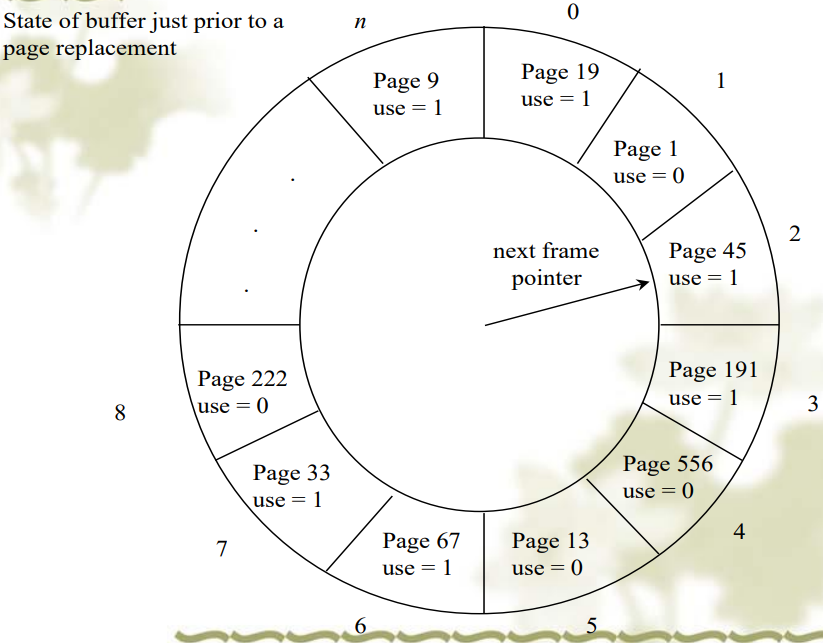
Not Recently Used(NRU)
- 给每个 page 加上引用位 R,修改位 M
- 当 page 被引用(read or write recently)或者修改(written to)时,把 R 或者 M 置 1
- 周期性(每个时钟周期)把 R 位清零
- 所以有四种类型的 page sets
| Type | R | M |
|---|---|---|
| Class 0 | 0 | 0 |
| Class 1 | 0 | 1 |
| Class 2 | 1 | 0 |
| Class 3 | 1 | 1 |
- 按 Class 0、1、2、3 的顺序进行 page replacement
Least Rencently Used(LRU)
- 假设最近使用的 page 不久又会被访问
软件实现
- 最常用的在队首,最少用的在队尾
- 每次内存访问都会更新这个 list
硬件实现 I
- 用一个 64 位计数器
- 每条指令递增这个计数器,然后再每个内存访问,这个计数器中的值被放在页表项中。然后选取这个值最小的页表项。
- 周期性地(就是所说的最近)对这个计数器置零
硬件实现 II
- 对一个有 n 个 page frame 的机器维护一个 n×n 的矩阵
- 当第 K 个 page frame 被引用时,把第 K 行全部置为 1,第 K 列全部置 0
- 要替换时,对应行二进制值最小的就是 LRU Page
NFU(Not Frequently Used)
- 就是对 LRU 的软件模拟,因为 LRU 软件实现太 expensive,硬件实现对硬件有要求难以实现
- 每个 page 都有一个计数器,在每个时钟周期,R 位加到计数器上,当 page fault 发生时,计数器最小值被替换,但是 NFU 没有遗忘机制,可能这个 page 是过去经常使用的,但是现在已经不怎么使用了
Modified NFU(NFU with Aging)
- 改进 NFU
- 每个时钟周期把 NFU 的计数器右移一位,然后把 R 位加到计数器的最高位,就可以保证给当前状态最高的优先级
Working Set Page Replacement
- 工作集(Working set) w(k,t)表示在 t 时间内最经常访问的 k 个页面,或者 ws(t)表示在过去的 t 时间内访问的所有页面
算法 I
- 每个时钟周期,清空所有 R 位
- 当需要置换时,遍历主存中所存储的所有 page
- 如果 R=1 就把当前时间 t 存储进当前 PTE 的 LTU(last time used)字段
- 如果 R=0:
- 如果
- 如果
算法 II(WSClock Page Replacement)
- 维护一个环形链表
当 page fault 发生时:
- 如果 R=1,就置 R=0,头指针前进一位继续遍历链表
- 如果 R=0
- 如果
- 如果
- 如果
但是有可能转了一圈都没发现可以用于换出的页:
- 如果找到一个或多余一个
- 最差的情况下,没有
全局置换和局部置换

- 局部置换就是在进程所有的 page 内进行置换
- 全局置换就是可以把其他进程的 page 用于置换
- workset 只能定义在某个进程中,因此也就只能用局部置换
Load Control
- 尽管我们有很好的算法,但是因为进程总是想要更多的内存,也会造成系统的颠簸(频繁 page fault)
- 所以我们要控制进程在内存中的数量,就可以减少对内存的竞争,可以通过把更多的内容存在硬盘中和控制程序的并行度来做到
Page Size
- 较小能带来更少的内部碎片和内存浪费,但是会导致页表更大
- 较大则反之
分离的指令和共享的数据
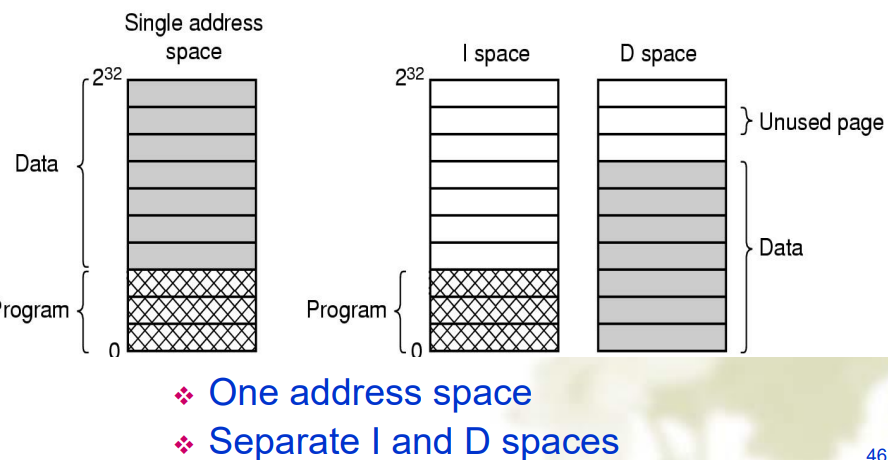
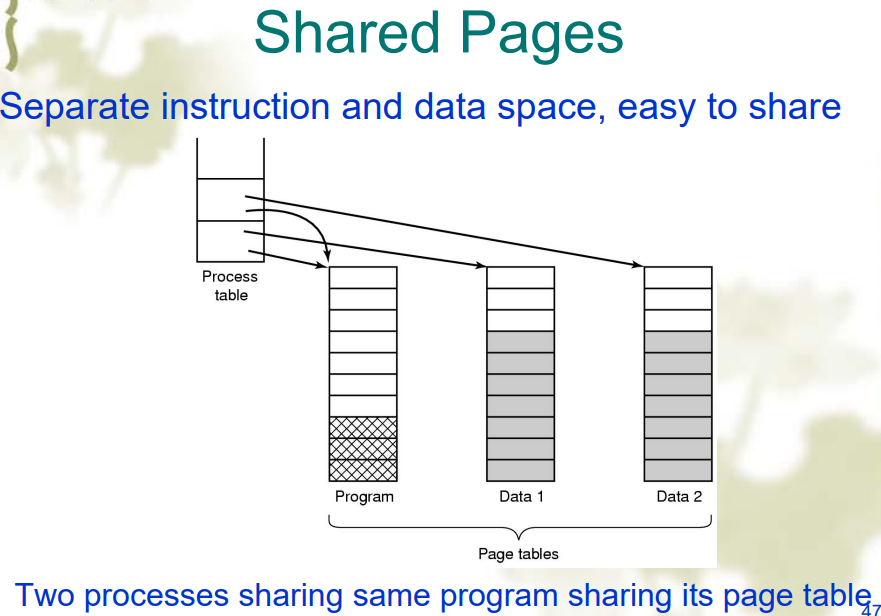
- 通过在 PCB 中用指针指向同一个页表来实现共享数据
Clean Policy
- 使用一个守护进程(Paging daemon)来检测内存状态
- 如果太少 page frame 可用了就用 replacement 算法换出一些 page
- 可以用前后指针的方式在之前的环形链表上运行
操作系统内的 Paging 操作
Page Fault 处理
- 硬件陷入内核,PC 保存到栈中
- 保存通用寄存器
- 操作系统决定用到的虚页
- 操作系统检查虚页地址的有效性,寻找 page frame
- 如果找到的 frame 是 dirty,写硬盘,暂时中断进程
- 操作系统从硬盘中加载一个 page,进程仍然中断
- 硬盘发出中断,页表更新
- 指令从 Page fault 的地方开始恢复
- Page fault 的进程开始调度
- 恢复寄存器
- 程序继续运行
Segmentation
基本概念
- 段式内存管理支持 user view of memory
- 一个程序是一个段的集合,每个段是一个逻辑单元,例如主程序、过程、函数、符号表、堆栈
段表和地址转换
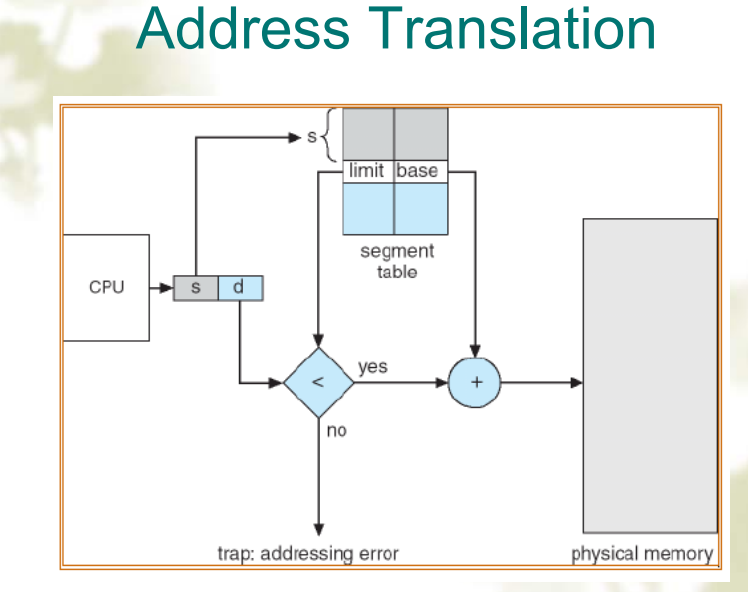
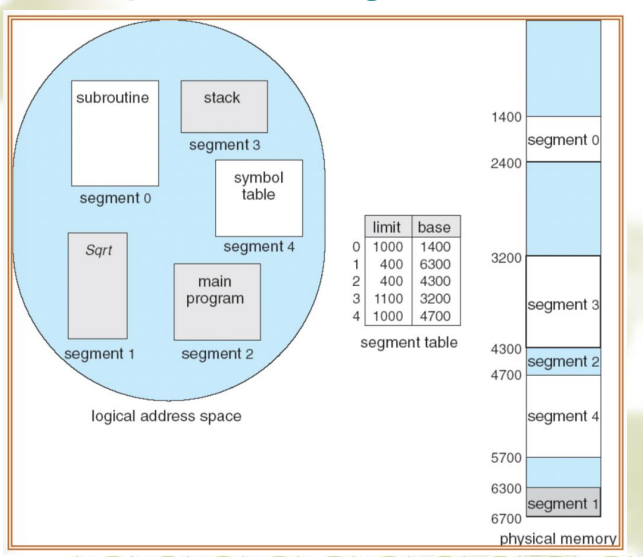
段 vs 页
| Consideration | 分页 | 分段 |
|---|---|---|
| 编程时需要特别关心? | No | Yes |
| 有多少线性的地址空间 | 1 | Many |
| 总地址空间可以比物理地址空间大吗 | Yes | Yes |
| 程序和数据可以被识别并且分别保护吗 | No | Yes |
| 可以轻松容纳大小变化的表吗 | No | Yes |
| 用户间共享程序是被支持的吗 | No | Yes |
| 这项技术为什么会被发明 | 为了在有限的物理内存中获取更大的线性地址空间 | 为了让程序和数据能被划分为逻辑上相互独立的地址空间,从而支持共享和保护 |
优缺点
优点
- 可以扩展、收缩段
- 每个段都可以被单独保护
- 可以在并行任务中链接程序
- 在进程间共享代码变得容易
缺点
- 程序员必须对内存模型的使用非常警惕
- 碎片会浪费大量空间
- 一个段可能大到物理内存无法容纳
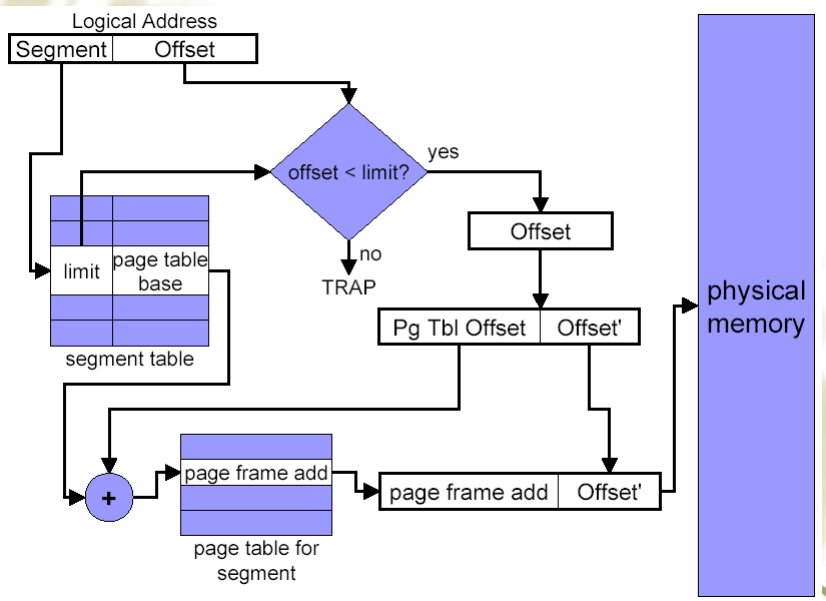
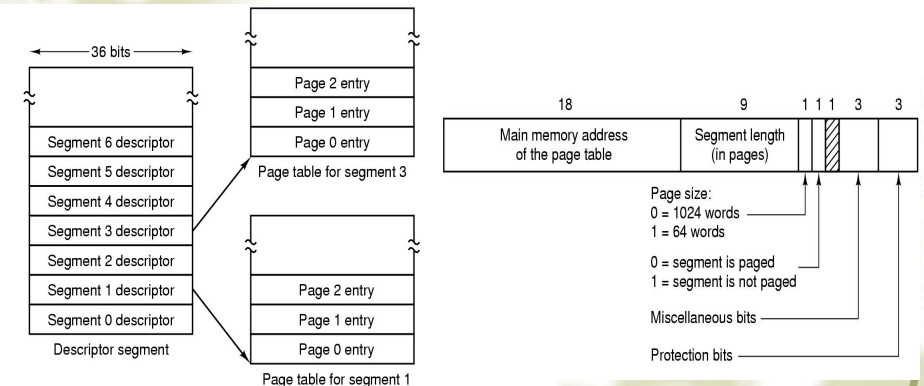
段页式(Segmentation with paging)
- 每个进程都有一个段表,这个段表本身也可能是分段分页的,段表中的每项都指向了这个段对应的页表(可能是多级的)
- 段被分为页,一个段的内容在内存中不再是连续的,也不是全都在内存中,因此每个段都要有一个页表,因此在段页式中,段的 base 值不再是段在内存中的起始地址,而是这个段的页表的起始地址
地址转换
TLB